HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

OpenComputer: Verifiable Software Worlds for Computer-Use Agents

Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information


























OpenComputer: Verifiable Software Worlds for Computer-Use Agents
Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Targeted Neuron Modulation via Contrastive Pair Search
Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
AI for Auto-Research: Roadmap & User Guide
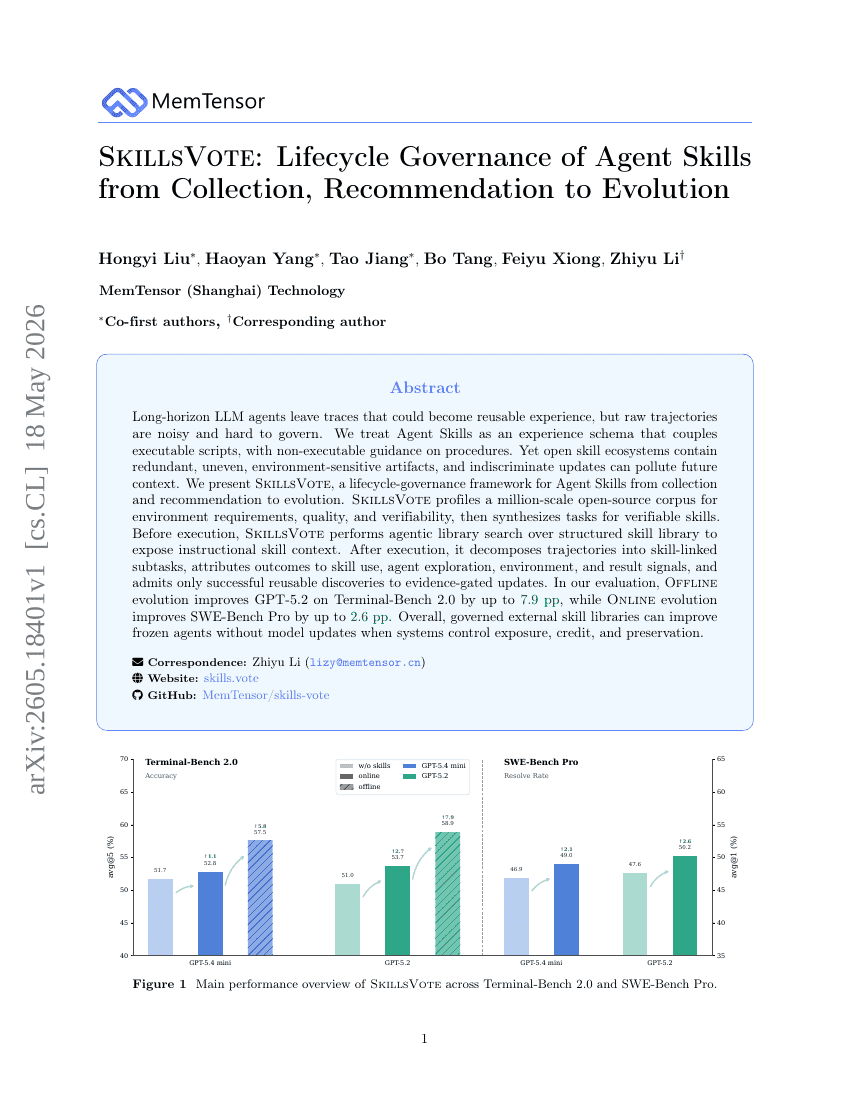
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
Lance: Unified Multimodal Modeling by Multi-Task Synergy
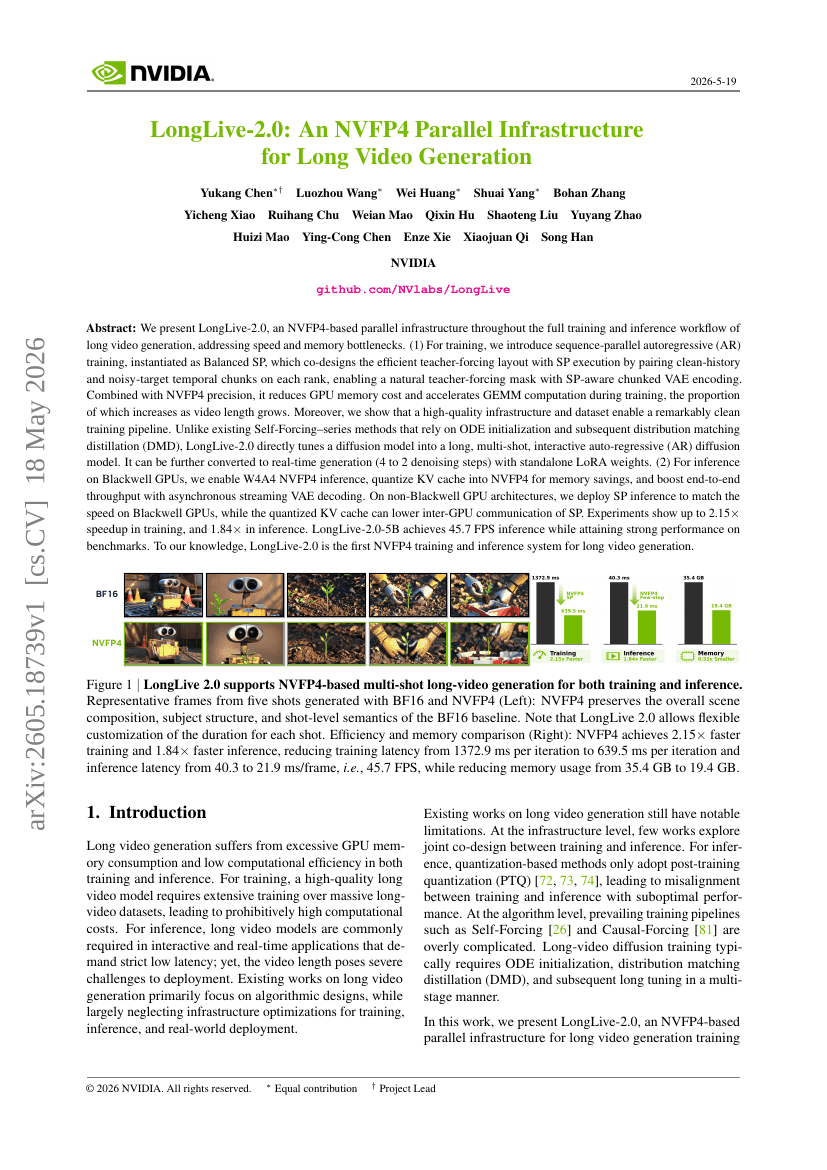
LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
Slicing and Dicing: Configuring Optimal Mixtures of Experts
Agentic Discovery of Neural Architectures: AIRA-Compose and AIRA-Design
Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
DexJoCo: A Benchmark and Toolkit for Task-Oriented Dexterous Manipulation on MuJoCo
FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
MMSkills: Towards Multimodal Skills for General Visual Agents
PhysBrain 1.0 Technical Report
Bringing Value Models Back: Generative Critics for Value Modeling in LLM Reinforcement Learning
NEXUS: An Agentic Framework for Time Series Forecasting
MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory
SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
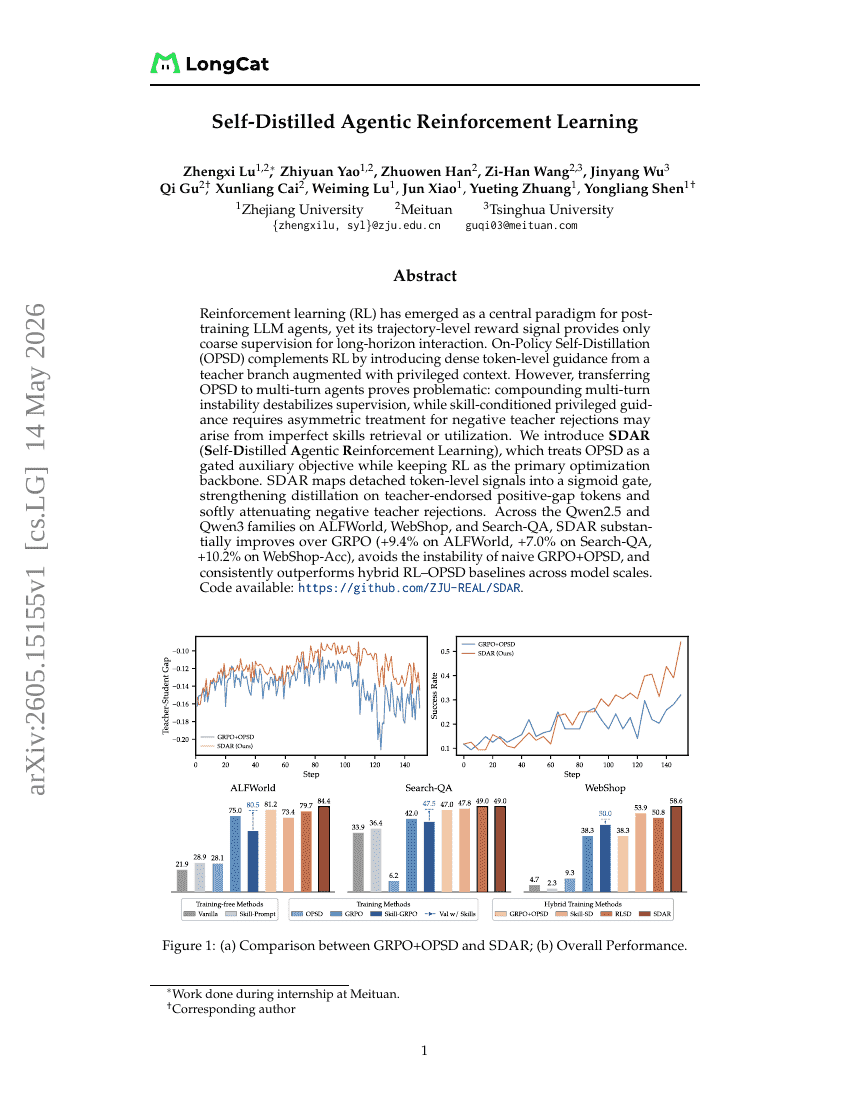
Self-Distilled Agentic Reinforcement Learning
Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
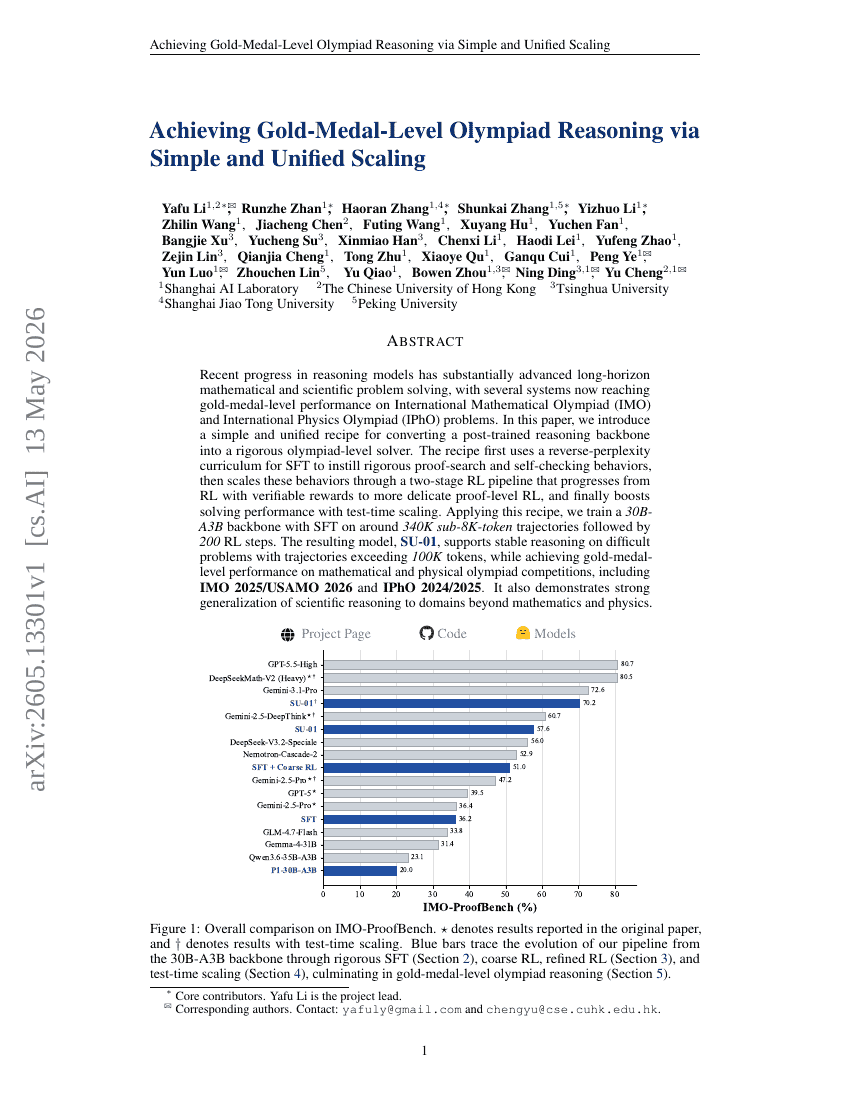
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
RepoZero: Can LLMs Generate a Code Repository from Scratch?
Qwen-Image-VAE-2.0 Technical Report
Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context
AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
MinT: Managed Infrastructure for Training and Serving Millions of LLMs
Targeted Neuron Modulation via Contrastive Pair Search
Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
AI for Auto-Research: Roadmap & User Guide
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
Lance: Unified Multimodal Modeling by Multi-Task Synergy
LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
Slicing and Dicing: Configuring Optimal Mixtures of Experts
Agentic Discovery of Neural Architectures: AIRA-Compose and AIRA-Design
Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
DexJoCo: A Benchmark and Toolkit for Task-Oriented Dexterous Manipulation on MuJoCo
FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
MMSkills: Towards Multimodal Skills for General Visual Agents
PhysBrain 1.0 Technical Report
Bringing Value Models Back: Generative Critics for Value Modeling in LLM Reinforcement Learning
NEXUS: An Agentic Framework for Time Series Forecasting
MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory
SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
Self-Distilled Agentic Reinforcement Learning
Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
RepoZero: Can LLMs Generate a Code Repository from Scratch?
Qwen-Image-VAE-2.0 Technical Report
Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context
AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
MinT: Managed Infrastructure for Training and Serving Millions of LLMs