HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
VLM-SlideEval:在PPT中评估VLMs的结构化理解与扰动敏感性
文档理解
基准
Hyeonsu Kang, Emily Bao, Anjan Goswami
TeraSim-World:面向端到端自动驾驶的全球安全关键数据合成
自动驾驶
地理信息
Jiawei Wang, Haowei Sun, Xintao Yan, et al.
前瞻锚定:在基于音频的人体动画中保持角色身份
视频生成
多模态
Junyoung Seo, Rodrigo Mira, Alexandros Haliassos, et al.
VITA-E:自然具身交互中的并发视觉、听觉、语言生成与行动
Agent
具身智能
Xiaoyu Liu, Chaoyou Fu, Chi Yan, et al.
FARMER:基于像素的流式自回归Transformer
图像生成
Transformer
Guangting Zheng, Qinyu Zhao, Tao Yang, et al.
数据Agent综述:新兴范式还是被夸大的炒作?
Agent
LLM
Yizhang Zhu, Liangwei Wang, Chenyu Yang, et al.
ReCode:统一规划与执行以实现通用粒度控制
语言
代码生成
Zhaoyang Yu, Jiayi Zhang, Huixue Su, et al.
Concerto:联合2D-3D自监督学习涌现空间表征
多模态表征
计算机视觉
Yujia Zhang, Xiaoyang Wu, Yixing Lao, et al.
Magellan:用于潜在空间探索与新颖性生成的引导式MCTS
LLM
文本生成
Lufan Chang
DEEDEE:快速且可扩展的分布外动态检测
强化学习
建模
Tala Aljaafari, Varun Kanade, Philip Torr, et al.
通过Token重排实现更稀疏的块稀疏注意力
Transformer
LLM
Xinghao Wang, Pengyu Wang, Dong Zhang, et al.
AGI的定义
基准
推理
Dan Hendrycks, Dawn Song, Christian Szegedy, et al.
从去噪到精炼:一种面向视觉-语言扩散模型的校正框架
扩散模型
多模态
Yatai Ji, Teng Wang, Yuying Ge, et al.
逐步采样,分块优化:面向文本到图像生成的分块级GRPO
文生图
图像生成
Yifu Luo, Penghui Du, Bo Li, et al.
视频作为提示:视频生成的统一语义控制
视频生成
图生视频
Yuxuan Bian, Xin Chen, Zenan Li, et al.
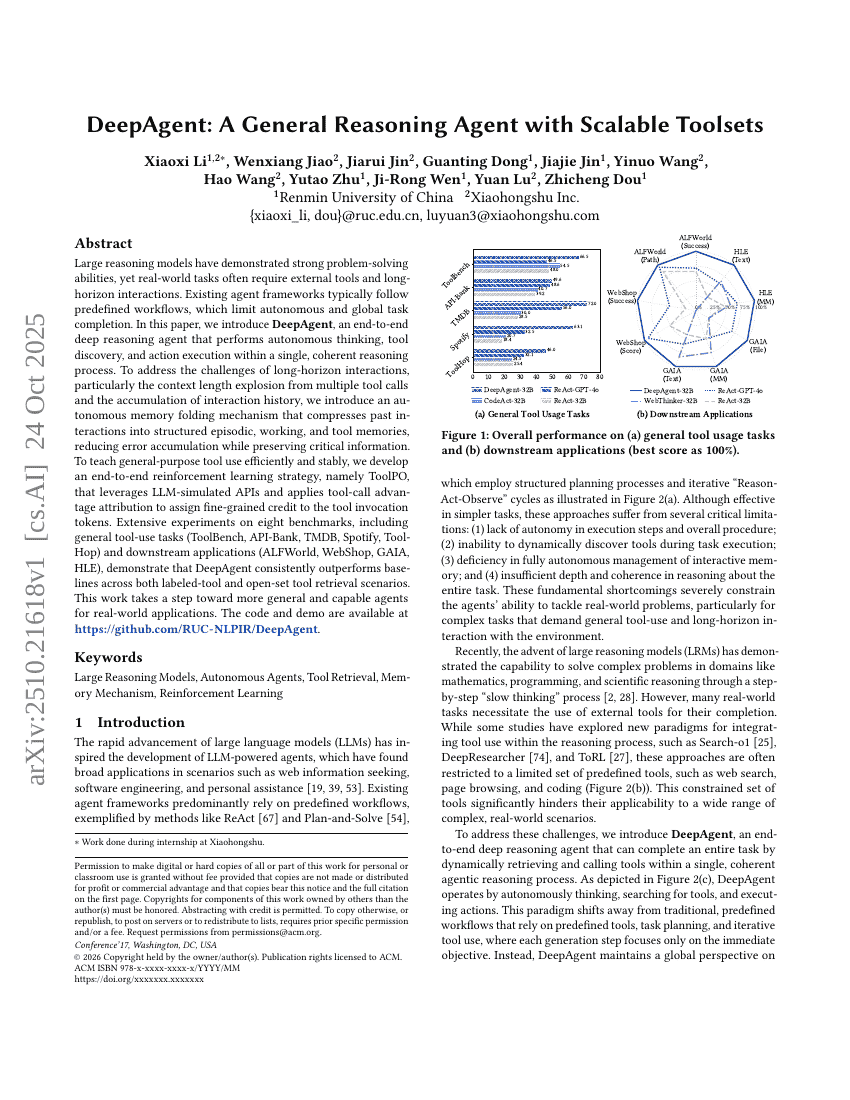
DeepAgent:具备可扩展工具集的通用推理Agent
Agent
推理
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, et al.
不确定性感知的多目标强化学习引导的扩散模型用于三维从头分子设计
扩散模型
强化学习
Lianghong Chen, Dongkyu Eugene Kim, Mike Domaratzki, et al.
Reac-Discovery:一种由人工智能驱动的连续流催化反应器发现与优化平台
AI for Science
建模
Cristopher Tinajero, Marcileia Zanatta, Julián E. Sánchez-Velandia, et al.
BoltzGen:迈向通用结合剂设计
AI for Science
深度学习
Hannes Stark, Felix Faltings, MinGyu Choi, et al.
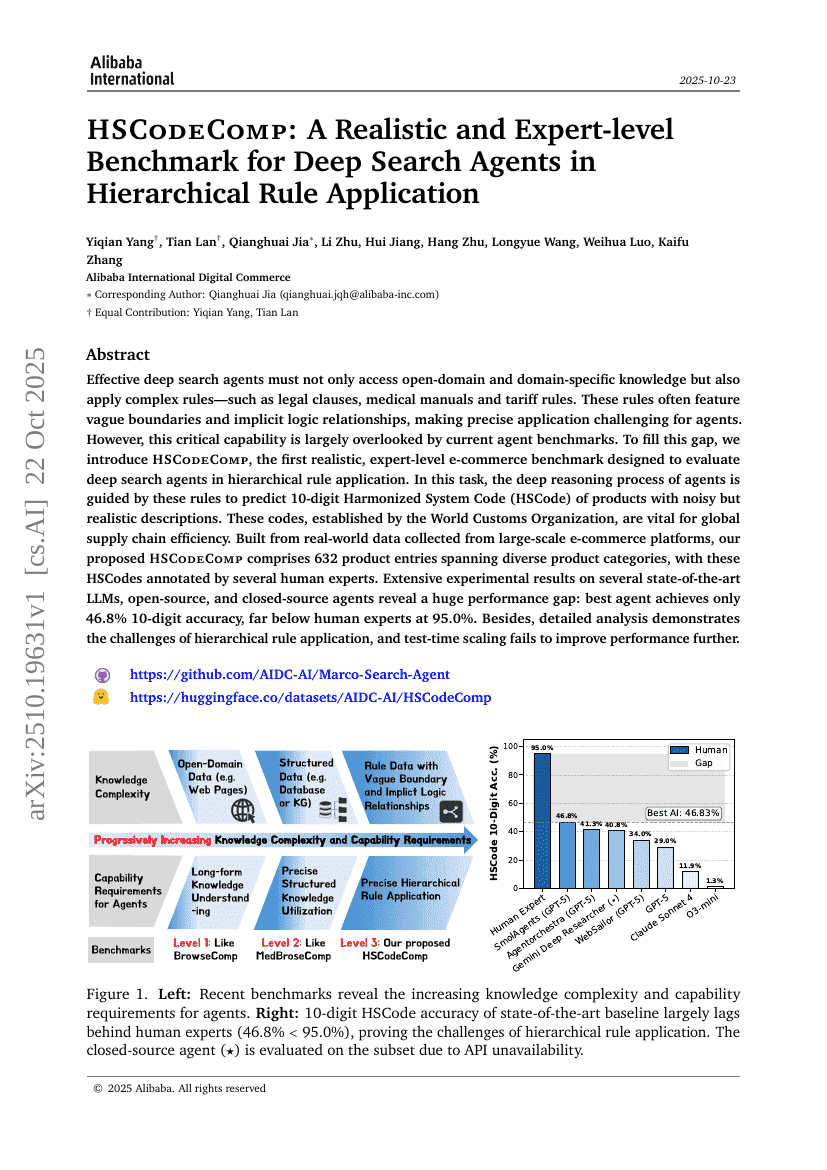
HSCodeComp:面向层级规则应用中深度搜索Agent的现实且专家级基准
基准
数据集
Yiqian Yang, Tian Lan, Qianghuai Jia, et al.
DyPE:用于超高分辨率扩散的动态位置外推
扩散模型
Transformer
Noam Issachar, Guy Yariv, Sagie Benaim, et al.
HoloCine:电影级多镜头长视频叙事的全局生成
文生视频
视频生成
Yihao Meng, Hao Ouyang, Yue Yu, et al.
Open-o3 Video:基于显式时空证据的视频推理
视频理解
推理
Jiahao Meng, Xiangtai Li, Haochen Wang, et al.
AdaSPEC:用于高效推测解码器的可选知识蒸馏
LLM
Transformer
Yuezhou Hu, Jiaxin Guo, Xinyu Feng, et al.
人类-Agent协同的论文到页面制作成本低于0.1美元
Agent
统一多模态
Qianli Ma, Siyu Wang, Yilin Chen, et al.
从Token化到视觉阅读
多模态
OCR
Ling Xing, Alex Jinpeng Wang, Rui Yan, et al.
用于微调MLLMs的定向推理注入
视觉问答
统一多模态
Chao Huang, Zeliang Zhang, Jiang Liu, et al.
语言模型是单射的,因此可逆
Transformer
自然语言处理
Giorgos Nikolaou, Tommaso Mencattini, Donato Crisostomi, et al.
自由Transformer
Transformer
统一多模态
François Fleuret
基于机器学习的量子处理单元(QPU)处理时间预测
机器学习
模型训练
Lucy Xing, Sanjay Vishwakarma, David Kremer, et al.
量子遍历性边缘的建设性干涉观测
AI for Science
建模
Google Quantum AI and Collaborators
VideoAgentTrek:从无标签视频中进行计算机使用预训练
动作识别
人机交互
Dunjie Lu, Yiheng Xu, Junli Wang, et al.
1
18
19
20
21
22
23
24
48
VLM-SlideEval:在PPT中评估VLMs的结构化理解与扰动敏感性
文档理解
基准
Hyeonsu Kang, Emily Bao, Anjan Goswami
TeraSim-World:面向端到端自动驾驶的全球安全关键数据合成
自动驾驶
地理信息
Jiawei Wang, Haowei Sun, Xintao Yan, et al.
前瞻锚定:在基于音频的人体动画中保持角色身份
视频生成
多模态
Junyoung Seo, Rodrigo Mira, Alexandros Haliassos, et al.
VITA-E:自然具身交互中的并发视觉、听觉、语言生成与行动
Agent
具身智能
Xiaoyu Liu, Chaoyou Fu, Chi Yan, et al.
FARMER:基于像素的流式自回归Transformer
图像生成
Transformer
Guangting Zheng, Qinyu Zhao, Tao Yang, et al.
数据Agent综述:新兴范式还是被夸大的炒作?
Agent
LLM
Yizhang Zhu, Liangwei Wang, Chenyu Yang, et al.
ReCode:统一规划与执行以实现通用粒度控制
语言
代码生成
Zhaoyang Yu, Jiayi Zhang, Huixue Su, et al.
Concerto:联合2D-3D自监督学习涌现空间表征
多模态表征
计算机视觉
Yujia Zhang, Xiaoyang Wu, Yixing Lao, et al.
Magellan:用于潜在空间探索与新颖性生成的引导式MCTS
LLM
文本生成
Lufan Chang
DEEDEE:快速且可扩展的分布外动态检测
强化学习
建模
Tala Aljaafari, Varun Kanade, Philip Torr, et al.
通过Token重排实现更稀疏的块稀疏注意力
Transformer
LLM
Xinghao Wang, Pengyu Wang, Dong Zhang, et al.
AGI的定义
基准
推理
Dan Hendrycks, Dawn Song, Christian Szegedy, et al.
从去噪到精炼:一种面向视觉-语言扩散模型的校正框架
扩散模型
多模态
Yatai Ji, Teng Wang, Yuying Ge, et al.
逐步采样,分块优化:面向文本到图像生成的分块级GRPO
文生图
图像生成
Yifu Luo, Penghui Du, Bo Li, et al.
视频作为提示:视频生成的统一语义控制
视频生成
图生视频
Yuxuan Bian, Xin Chen, Zenan Li, et al.
DeepAgent:具备可扩展工具集的通用推理Agent
Agent
推理
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, et al.
不确定性感知的多目标强化学习引导的扩散模型用于三维从头分子设计
扩散模型
强化学习
Lianghong Chen, Dongkyu Eugene Kim, Mike Domaratzki, et al.
Reac-Discovery:一种由人工智能驱动的连续流催化反应器发现与优化平台
AI for Science
建模
Cristopher Tinajero, Marcileia Zanatta, Julián E. Sánchez-Velandia, et al.
BoltzGen:迈向通用结合剂设计
AI for Science
深度学习
Hannes Stark, Felix Faltings, MinGyu Choi, et al.
HSCodeComp:面向层级规则应用中深度搜索Agent的现实且专家级基准
基准
数据集
Yiqian Yang, Tian Lan, Qianghuai Jia, et al.
DyPE:用于超高分辨率扩散的动态位置外推
扩散模型
Transformer
Noam Issachar, Guy Yariv, Sagie Benaim, et al.
HoloCine:电影级多镜头长视频叙事的全局生成
文生视频
视频生成
Yihao Meng, Hao Ouyang, Yue Yu, et al.
Open-o3 Video:基于显式时空证据的视频推理
视频理解
推理
Jiahao Meng, Xiangtai Li, Haochen Wang, et al.
AdaSPEC:用于高效推测解码器的可选知识蒸馏
LLM
Transformer
Yuezhou Hu, Jiaxin Guo, Xinyu Feng, et al.
人类-Agent协同的论文到页面制作成本低于0.1美元
Agent
统一多模态
Qianli Ma, Siyu Wang, Yilin Chen, et al.
从Token化到视觉阅读
多模态
OCR
Ling Xing, Alex Jinpeng Wang, Rui Yan, et al.
用于微调MLLMs的定向推理注入
视觉问答
统一多模态
Chao Huang, Zeliang Zhang, Jiang Liu, et al.
语言模型是单射的,因此可逆
Transformer
自然语言处理
Giorgos Nikolaou, Tommaso Mencattini, Donato Crisostomi, et al.
自由Transformer
Transformer
统一多模态
François Fleuret
基于机器学习的量子处理单元(QPU)处理时间预测
机器学习
模型训练
Lucy Xing, Sanjay Vishwakarma, David Kremer, et al.
量子遍历性边缘的建设性干涉观测
AI for Science
建模
Google Quantum AI and Collaborators
VideoAgentTrek:从无标签视频中进行计算机使用预训练
动作识别
人机交互
Dunjie Lu, Yiheng Xu, Junli Wang, et al.
1
18
19
20
21
22
23
24
48