HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
具有表示自编码器的扩散Transformer
扩散模型
图像生成
Boyang Zheng, Nanye Ma, Shengbang Tong, et al.
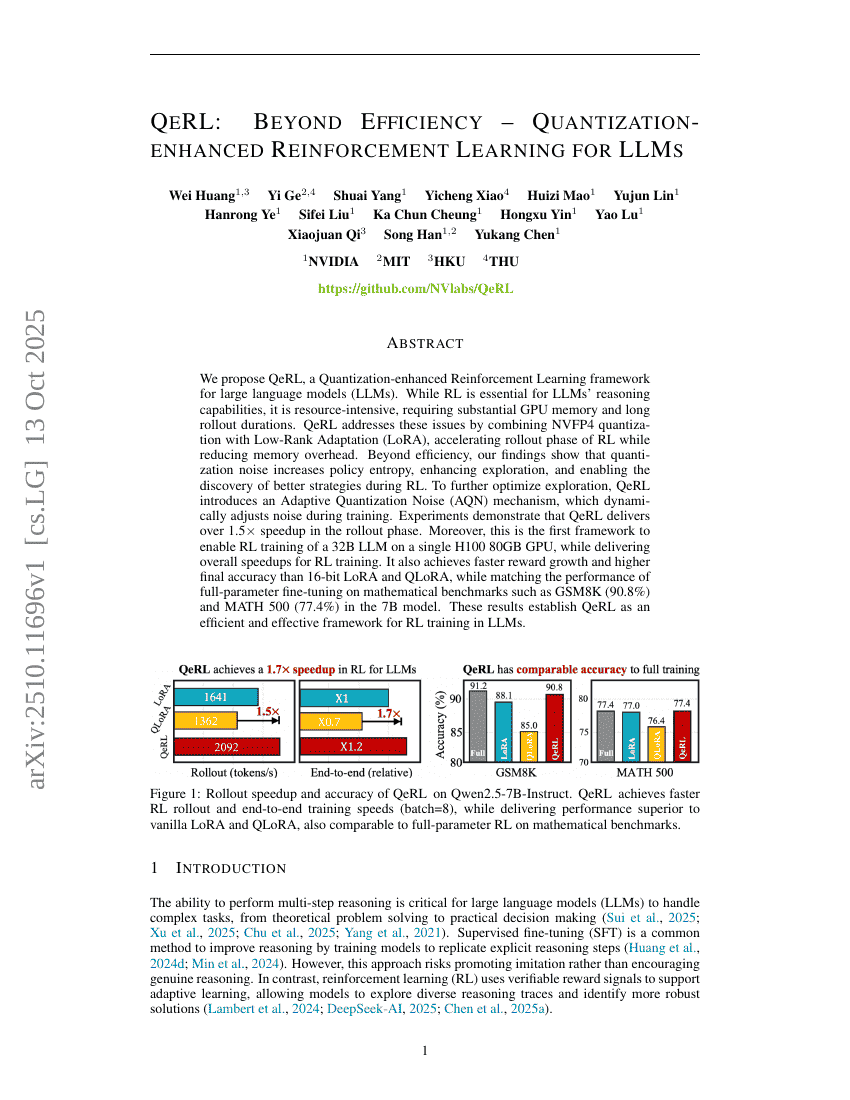
QeRL:超越效率——面向LLMs的量化增强型强化学习
强化学习
模型训练
Wei Huang, Yi Ge, Shuai Yang, et al.
无需反向传播的威尔逊环:一种用于检测不变性与顺序敏感性的实用诊断方法
Transformer
监督式微调
Edward Y. Chang, Ethan Y. Chang
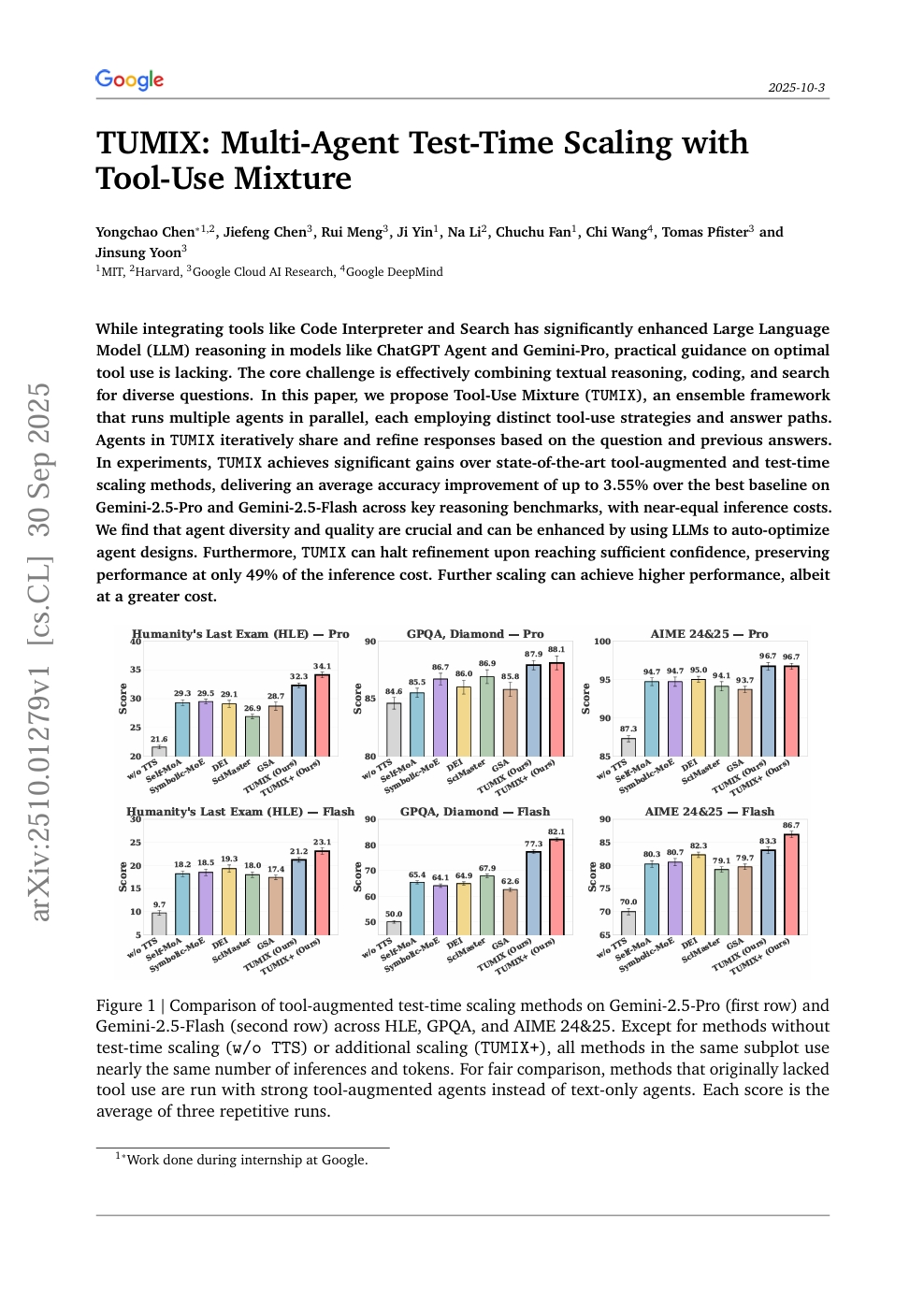
TUMIX:带有工具使用混合的多Agent测试时扩展
Agent
推理
Yongchao Chen, Jiefeng Chen, Rui Meng, et al.
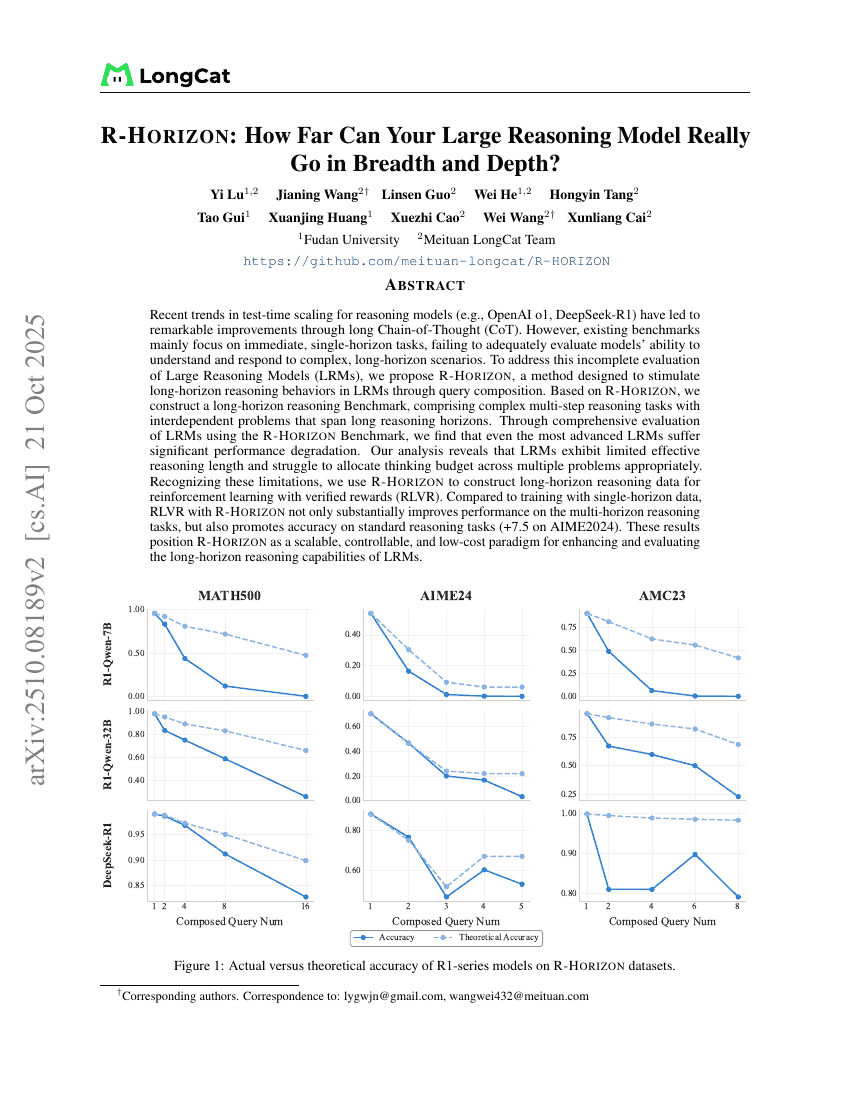
R-Horizon:你的大型推理模型在广度与深度上究竟能走多远?
推理
基准
Yi Lu, Jianing Wang, Linsen Guo, et al.
AutoPR:让我们自动化你的学术晋升!
基准
多模态
Qiguang Chen, Zheng Yan, Mingda Yang, et al.
多模态提示优化:为何不利用多种模态来提升MLLMs?
多模态
统一多模态
Yumin Choi, Dongki Kim, Jinheon Baek, et al.
旁路增强引导用于幻觉抑制的扩散采样
扩散模型
图像生成
Hyunmin Cho, Donghoon Ahn, Susung Hong, et al.
用相机思考:一种面向以相机为中心的感知与生成的统一多模态模型
多模态
统一多模态
Kang Liao, Size Wu, Zhonghua Wu, et al.
D2E:在桌面数据上扩展视觉-动作预训练以实现向具身AI的迁移
具身智能
统一多模态
Suwhan Choi, Jaeyoon Jung, Haebin Seong, et al.
Code2Video:一种以代码为中心的教育视频生成范式
视频生成
代码生成
Yanzhe Chen, Kevin Qinghong Lin, Mike Zheng Shou
博士偏见:人工智能驱动的医疗指导中的社会不平等
自然语言处理
医学
Emma Kondrup, Anne Imouza
LLM的二阶优化潜力:基于完整高斯-牛顿法的研究
Transformer
LLM
Natalie Abreu, Nikhil Vyas, Sham Kakade, et al.
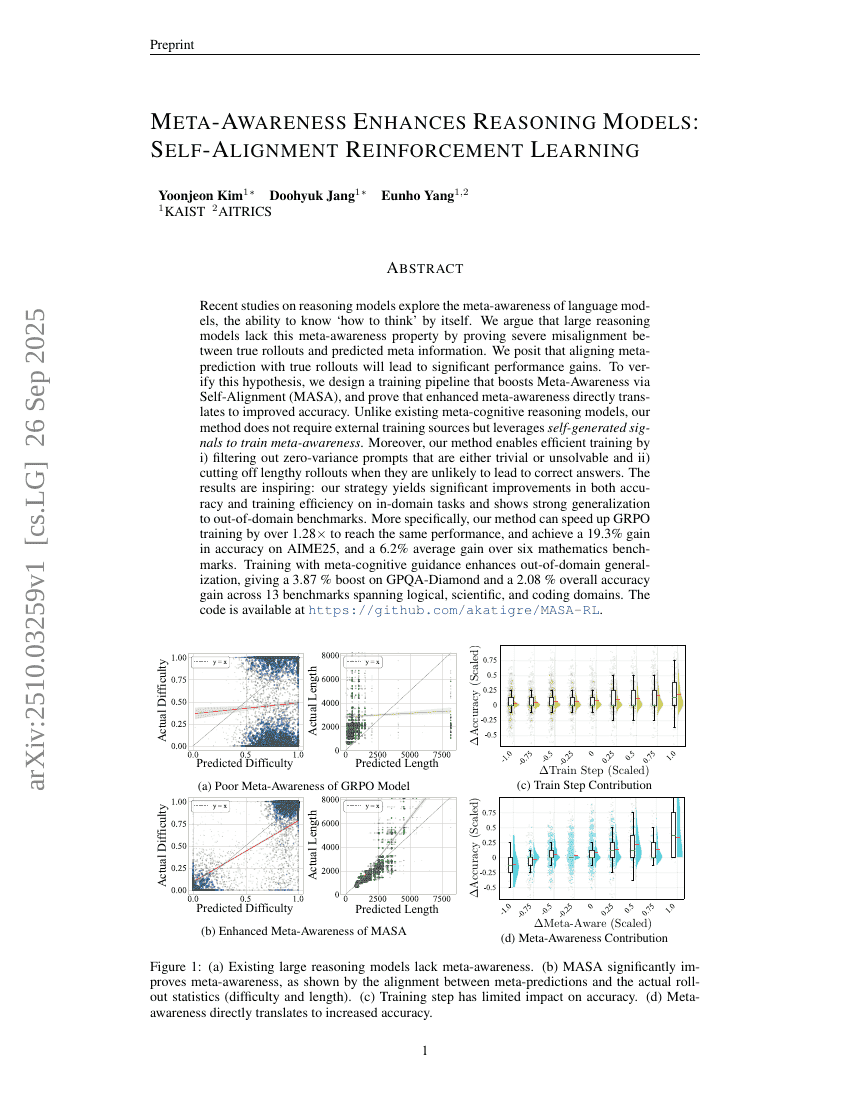
元认知增强推理模型:自对齐强化学习
推理
LLM
Yoonjeon Kim, Doohyuk Jang, Eunho Yang
从何到因:一种基于证据的化学反应条件推理多Agent系统
Agent
检索增强生成
Cheng Yang, Jiaxuan Lu, Haiyuan Wan, et al.
DreamOmni2:基于多模态指令的编辑与生成
多模态
图像生成
Bin Xia, Bohao Peng, Yuechen Zhang, et al.
VideoCanvas:通过上下文条件实现任意时空补丁的统一视频补全
视频生成
图像修复
Minghong Cai, Qiulin Wang, Zongli Ye, et al.
UniVideo:视频的统一理解、生成与编辑
统一多模态
视频生成
Cong Wei, Quande Liu, Zixuan Ye, et al.
MemMamba:重新思考状态空间模型中的记忆模式
Transformer
自然语言处理
Youjin Wang, Yangjingyi Chen, Jiahao Yan, et al.
MM-HELIX:通过整体平台与自适应混合策略优化提升多模态长链反思推理
多模态
推理
Xiangyu Zhao, Junming Lin, Tianhao Liang, et al.
PromptCoT 2.0:面向大型语言模型推理的提示合成扩展
LLM
推理
Xueliang Zhao, Wei Wu, Jian Guan, et al.
Extract-0:用于文档信息提取的专用语言模型
监督式微调
文档理解
Henrique Godoy
OmniRetarget:面向人形机器人全身运动与操作及场景交互的交互保持型数据生成
机器人技术
强化学习
Lujie Yang, Xiaoyu Huang, Zhen Wu, et al.
WildSpeech-Bench:在真实场景中对端到端SpeechLLM进行基准测试
基准
音频和语音处理
Linhao Zhang, Jian Zhang, Bokai Lei, et al.
针对大型语言模型对齐的内部激活值的Token感知编辑
LLM
监督式微调
Tianbo Wang, Yuqing Ma, Kewei Liao, et al.
旨在学习:面向低资源视觉-语言建模的Token级动态门控
视觉问答
Transformer
Bianca-Mihaela Ganescu, Suchir Salhan, Andrew Caines, et al.
通过早期经验进行Agent学习
监督式微调
强化学习
Kai Zhang, Xiangchao Chen, Bo Liu, et al.
MATRIX:用于交互感知视频生成的掩码轨迹对齐
视频生成
文生视频
Siyoon Jin, Seongchan Kim, Dahyun Chung, et al.
RLinf-VLA:一种统一且高效的VLA+RL训练框架
强化学习
多模态表征
Hongzhi Zang, Mingjie Wei, Si Xu, et al.
SHANKS:用于语音语言模型的同步听与思
音频和语音处理
人机交互
Cheng-Han Chiang, Xiaofei Wang, Linjie Li, et al.
Lumina-DiMOO:一种用于多模态生成与理解的全模态扩散大型语言模型
统一多模态
扩散模型
Yi Xin, Qi Qin, Siqi Luo, et al.
缓存到缓存:大型语言模型之间的直接语义通信
LLM
Transformer
Tianyu Fu, Zihan Min, Hanling Zhang, et al.
1
21
22
23
24
25
26
27
48
具有表示自编码器的扩散Transformer
扩散模型
图像生成
Boyang Zheng, Nanye Ma, Shengbang Tong, et al.
QeRL:超越效率——面向LLMs的量化增强型强化学习
强化学习
模型训练
Wei Huang, Yi Ge, Shuai Yang, et al.
无需反向传播的威尔逊环:一种用于检测不变性与顺序敏感性的实用诊断方法
Transformer
监督式微调
Edward Y. Chang, Ethan Y. Chang
TUMIX:带有工具使用混合的多Agent测试时扩展
Agent
推理
Yongchao Chen, Jiefeng Chen, Rui Meng, et al.
R-Horizon:你的大型推理模型在广度与深度上究竟能走多远?
推理
基准
Yi Lu, Jianing Wang, Linsen Guo, et al.
AutoPR:让我们自动化你的学术晋升!
基准
多模态
Qiguang Chen, Zheng Yan, Mingda Yang, et al.
多模态提示优化:为何不利用多种模态来提升MLLMs?
多模态
统一多模态
Yumin Choi, Dongki Kim, Jinheon Baek, et al.
旁路增强引导用于幻觉抑制的扩散采样
扩散模型
图像生成
Hyunmin Cho, Donghoon Ahn, Susung Hong, et al.
用相机思考:一种面向以相机为中心的感知与生成的统一多模态模型
多模态
统一多模态
Kang Liao, Size Wu, Zhonghua Wu, et al.
D2E:在桌面数据上扩展视觉-动作预训练以实现向具身AI的迁移
具身智能
统一多模态
Suwhan Choi, Jaeyoon Jung, Haebin Seong, et al.
Code2Video:一种以代码为中心的教育视频生成范式
视频生成
代码生成
Yanzhe Chen, Kevin Qinghong Lin, Mike Zheng Shou
博士偏见:人工智能驱动的医疗指导中的社会不平等
自然语言处理
医学
Emma Kondrup, Anne Imouza
LLM的二阶优化潜力:基于完整高斯-牛顿法的研究
Transformer
LLM
Natalie Abreu, Nikhil Vyas, Sham Kakade, et al.
元认知增强推理模型:自对齐强化学习
推理
LLM
Yoonjeon Kim, Doohyuk Jang, Eunho Yang
从何到因:一种基于证据的化学反应条件推理多Agent系统
Agent
检索增强生成
Cheng Yang, Jiaxuan Lu, Haiyuan Wan, et al.
DreamOmni2:基于多模态指令的编辑与生成
多模态
图像生成
Bin Xia, Bohao Peng, Yuechen Zhang, et al.
VideoCanvas:通过上下文条件实现任意时空补丁的统一视频补全
视频生成
图像修复
Minghong Cai, Qiulin Wang, Zongli Ye, et al.
UniVideo:视频的统一理解、生成与编辑
统一多模态
视频生成
Cong Wei, Quande Liu, Zixuan Ye, et al.
MemMamba:重新思考状态空间模型中的记忆模式
Transformer
自然语言处理
Youjin Wang, Yangjingyi Chen, Jiahao Yan, et al.
MM-HELIX:通过整体平台与自适应混合策略优化提升多模态长链反思推理
多模态
推理
Xiangyu Zhao, Junming Lin, Tianhao Liang, et al.
PromptCoT 2.0:面向大型语言模型推理的提示合成扩展
LLM
推理
Xueliang Zhao, Wei Wu, Jian Guan, et al.
Extract-0:用于文档信息提取的专用语言模型
监督式微调
文档理解
Henrique Godoy
OmniRetarget:面向人形机器人全身运动与操作及场景交互的交互保持型数据生成
机器人技术
强化学习
Lujie Yang, Xiaoyu Huang, Zhen Wu, et al.
WildSpeech-Bench:在真实场景中对端到端SpeechLLM进行基准测试
基准
音频和语音处理
Linhao Zhang, Jian Zhang, Bokai Lei, et al.
针对大型语言模型对齐的内部激活值的Token感知编辑
LLM
监督式微调
Tianbo Wang, Yuqing Ma, Kewei Liao, et al.
旨在学习:面向低资源视觉-语言建模的Token级动态门控
视觉问答
Transformer
Bianca-Mihaela Ganescu, Suchir Salhan, Andrew Caines, et al.
通过早期经验进行Agent学习
监督式微调
强化学习
Kai Zhang, Xiangchao Chen, Bo Liu, et al.
MATRIX:用于交互感知视频生成的掩码轨迹对齐
视频生成
文生视频
Siyoon Jin, Seongchan Kim, Dahyun Chung, et al.
RLinf-VLA:一种统一且高效的VLA+RL训练框架
强化学习
多模态表征
Hongzhi Zang, Mingjie Wei, Si Xu, et al.
SHANKS:用于语音语言模型的同步听与思
音频和语音处理
人机交互
Cheng-Han Chiang, Xiaofei Wang, Linjie Li, et al.
Lumina-DiMOO:一种用于多模态生成与理解的全模态扩散大型语言模型
统一多模态
扩散模型
Yi Xin, Qi Qin, Siqi Luo, et al.
缓存到缓存:大型语言模型之间的直接语义通信
LLM
Transformer
Tianyu Fu, Zihan Min, Hanling Zhang, et al.
1
21
22
23
24
25
26
27
48