HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
孔子代码Agent:面向真实代码库的可扩展Agent框架
Agent
代码生成
Sherman Wong, Zhenting Qi, Zhaodong Wang, et al.
DreamStyle:一种统一的视频风格化框架
图生视频
视频处理
Mengtian Li, Jinshu Chen, Songtao Zhao, et al.
UniCorn:通过自生成监督实现自我提升的统一多模态模型
文生图
图像生成
Ruiyan Han, Zhen Fang, XinYu Sun, et al.
LTX-2:高效联合音视频基础模型
文生视频
扩散模型
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, et al.
SciEvalKit:面向科学通用智能的开源评估工具包
基准
开源
Yiheng Wang, Yixin Chen, Shuo Li, et al.
MOSS 语音转写与说话人分离:支持说话人分离的精准语音转写
音频和语音处理
LLM
Donghua Yu, Zhengyuan Lin, Chen Yang, et al.
InfiniDepth:基于神经隐式场的任意分辨率与细粒度深度估计
深度估计
机器视觉 3D
Hao Yu, Haotong Lin, Jiawei Wang, et al.
代理型AI的适应性调整
Agent
推理
Pengcheng Jiang, Jiacheng Lin, Zhiyi Shi, et al.
大型视频规划器实现可泛化的机器人控制
机器人技术
具身智能
Boyuan Chen, Tianyuan Zhang, Haoran Geng, et al.
InfiniteVGGT:面向无限数据流的视觉几何基底Transformer
建筑
机器视觉 3D
Shuai Yuan, Yantai Yang, Xiaotian Yang, et al.
GARDO:防止奖励劫持的扩散模型强化方法
强化学习
扩散模型
Haoran He, Yuxiao Ye, Jie Liu, et al.
VAR RL 正确实现:应对视觉自回归生成中的异步策略冲突
强化学习
扩散模型
Shikun Sun, Liao Qu, Huichao Zhang, et al.
DreamID-V:通过扩散Transformer弥合图像到视频的鸿沟实现高保真人脸替换
图生视频
扩散模型
Xu Guo, Fulong Ye, Xinghui Li, et al.
NextFlow:统一的序列建模激活多模态理解与生成
文生图
图像生成
Huichao Zhang, Liao Qu, Yiheng Liu, et al.
K-EXAONE 技术报告
LLM
文本生成
Eunbi Choi, Kibong Choi, Seokhee Hong, et al.
Hunger Game Debate:多智能体系统中过度竞争的涌现
Agent
LLM
Xinbei Ma, Ruotian Ma, Xingyu Chen, et al.
使用评分标准奖励训练AI协作者科学家
Agent
推理
Shashwat Goel, Rishi Hazra, Dulhan Jayalath, et al.
AdaGaR:面向动态场景重建的自适应Gabor表示
机器视觉 3D
深度估计
Jiewen Chan, Zhenjun Zhao, Yu-Lun Liu
驯服幻觉:通过反事实视频生成提升MLLMs的视频理解能力
扩散模型
视频理解
Zhe Huang, Hao Wen, Aiming Hao, et al.
SenseNova-MARS:通过强化学习赋能多模态智能体推理与搜索
Agent
多模态表征
Yong Xien Chng, Tao Hu, Wenwen Tong, et al.
Avatar Forcing:面向自然对话的实时交互式头部虚拟形象生成
人机交互
具身智能
Taekyung Ki, Sangwon Jang, Jaehyeong Jo, et al.
NeoVerse:利用真实场景单目视频增强4D世界模型
视频生成
3D 模型
Yuxue Yang, Lue Fan, Ziqi Shi, et al.
Youtu-Agent:基于自动化生成与混合策略优化的Agent生产率提升
Agent
LLM
Yuchen Shi, Yuzheng Cai, Siqi Cai, et al.
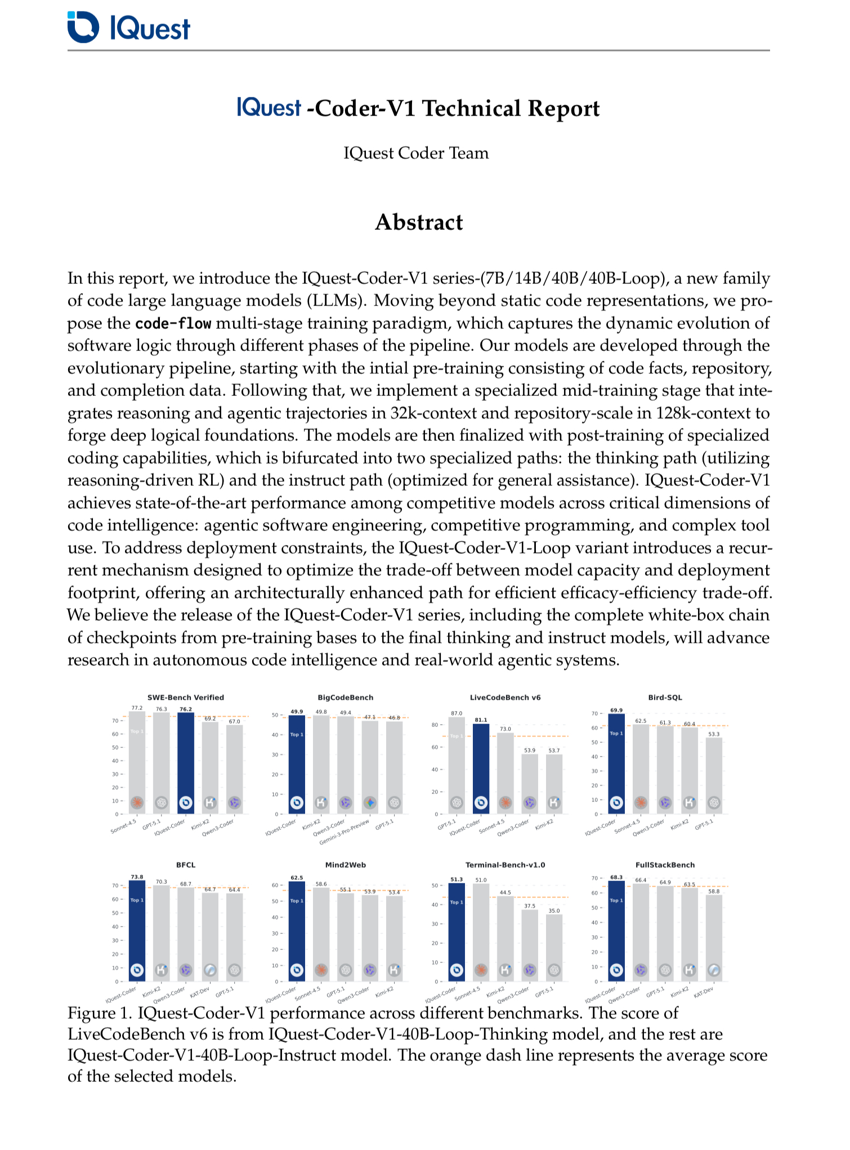
IQuest-Coder-V1 技术报告
代码生成
Agent
Jian Yang, Wei Zhang, Shawn Guo, et al.
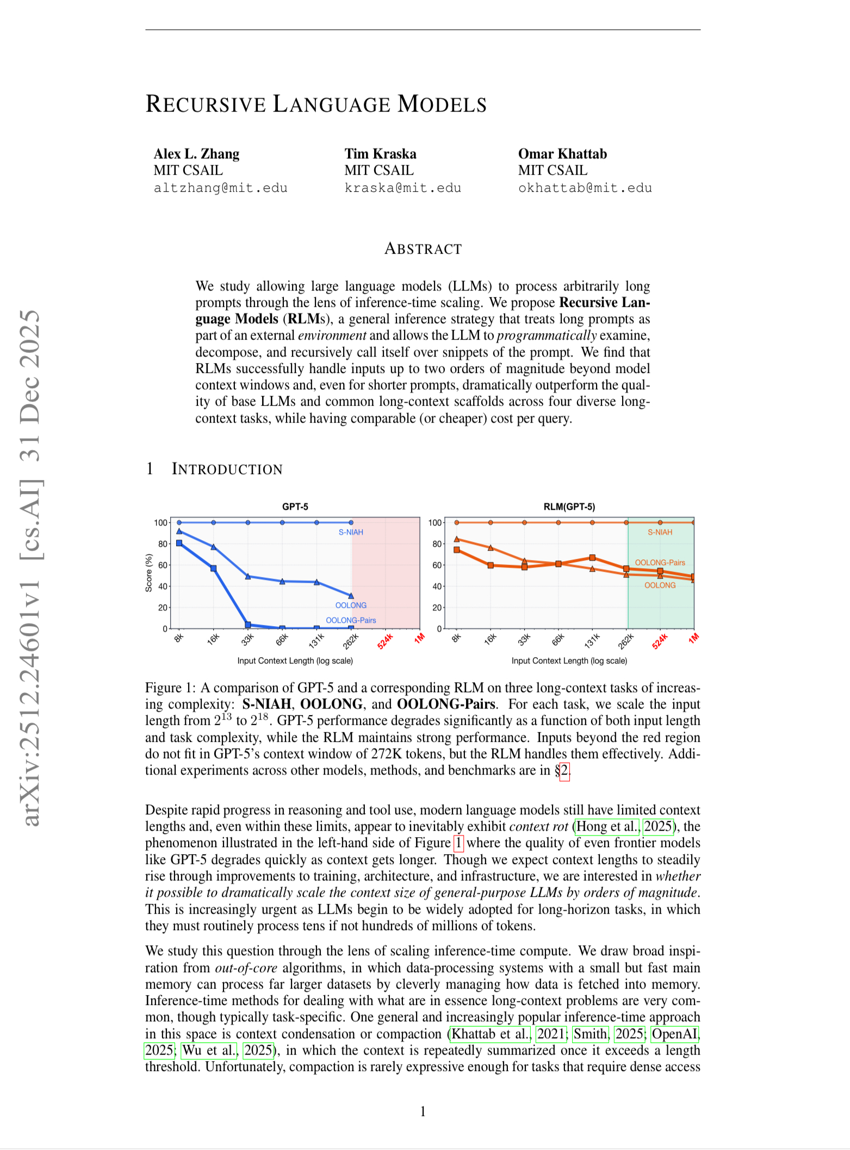
递归语言模型
LLM
Agent
Alex L. Zhang, Tim Kraska, Omar Khattab
FlowBlending:面向快速高保真视频生成的阶段感知多模型采样
视频生成
扩散模型
Jibin Song, Mingi Kwon, Jaeseok Jeong, et al.
Dream2Flow:基于3D物体流连接视频生成与开放世界操控
视频生成
机器人技术
Karthik Dharmarajan, Wenlong Huang, Jiajun Wu, et al.
扩散LLM中的离散性作用
扩散模型
LLM
Ziqi Jin, Bin Wang, Xiang Lin, et al.
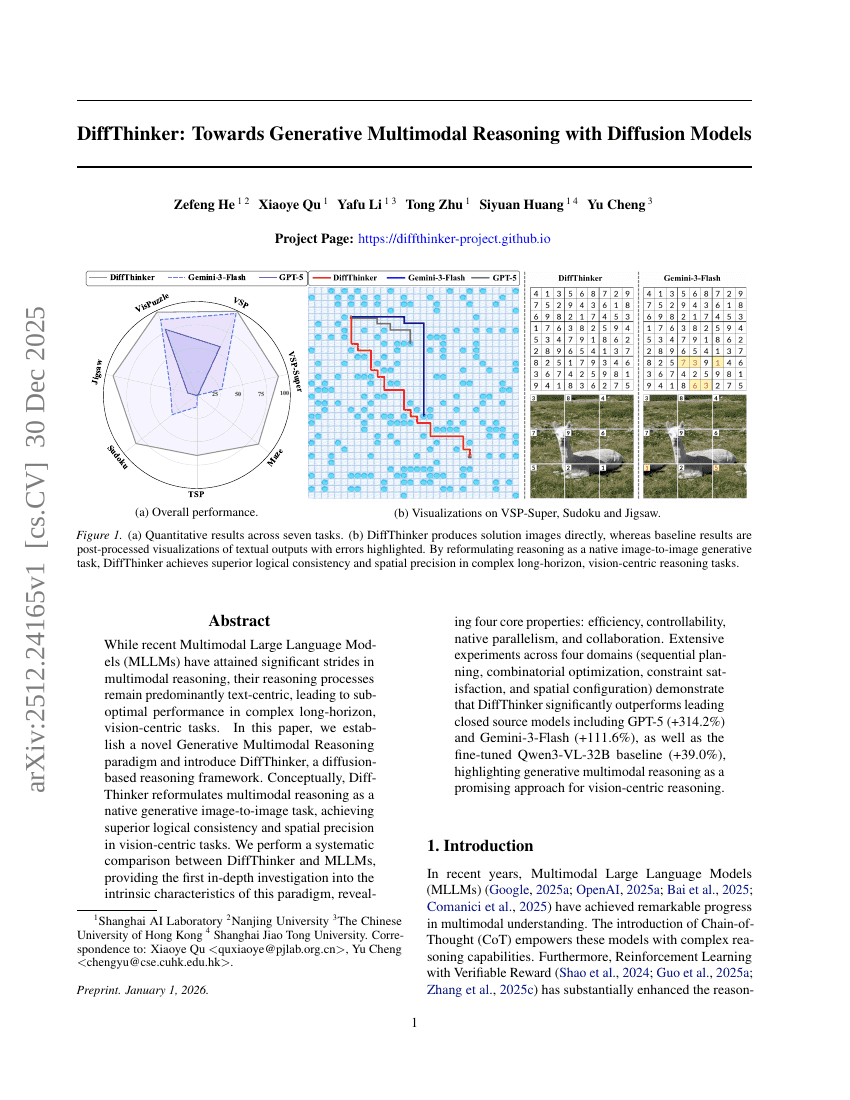
DiffThinker:面向生成式多模态推理的扩散模型
扩散模型
推理
Zefeng He, Xiaoye Qu, Yafu Li, et al.
动态大概念模型:自适应语义空间中的潜在推理
LLM
自然语言处理
Xingwei Qu, Shaowen Wang, Zihao Huang, et al.
基于超图记忆的多步RAG在长上下文复杂关系建模中的优化
检索增强生成
推理
Chulun Zhou, Chunkang Zhang, Guoxin Yu, et al.
人工智能与大脑的交汇:从认知神经科学到自主智能体的记忆系统
Agent
LLM
Jiafeng Liang, Hao Li, Chang Li, et al.
1
3
4
5
6
7
8
9
48
孔子代码Agent:面向真实代码库的可扩展Agent框架
Agent
代码生成
Sherman Wong, Zhenting Qi, Zhaodong Wang, et al.
DreamStyle:一种统一的视频风格化框架
图生视频
视频处理
Mengtian Li, Jinshu Chen, Songtao Zhao, et al.
UniCorn:通过自生成监督实现自我提升的统一多模态模型
文生图
图像生成
Ruiyan Han, Zhen Fang, XinYu Sun, et al.
LTX-2:高效联合音视频基础模型
文生视频
扩散模型
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, et al.
SciEvalKit:面向科学通用智能的开源评估工具包
基准
开源
Yiheng Wang, Yixin Chen, Shuo Li, et al.
MOSS 语音转写与说话人分离:支持说话人分离的精准语音转写
音频和语音处理
LLM
Donghua Yu, Zhengyuan Lin, Chen Yang, et al.
InfiniDepth:基于神经隐式场的任意分辨率与细粒度深度估计
深度估计
机器视觉 3D
Hao Yu, Haotong Lin, Jiawei Wang, et al.
代理型AI的适应性调整
Agent
推理
Pengcheng Jiang, Jiacheng Lin, Zhiyi Shi, et al.
大型视频规划器实现可泛化的机器人控制
机器人技术
具身智能
Boyuan Chen, Tianyuan Zhang, Haoran Geng, et al.
InfiniteVGGT:面向无限数据流的视觉几何基底Transformer
建筑
机器视觉 3D
Shuai Yuan, Yantai Yang, Xiaotian Yang, et al.
GARDO:防止奖励劫持的扩散模型强化方法
强化学习
扩散模型
Haoran He, Yuxiao Ye, Jie Liu, et al.
VAR RL 正确实现:应对视觉自回归生成中的异步策略冲突
强化学习
扩散模型
Shikun Sun, Liao Qu, Huichao Zhang, et al.
DreamID-V:通过扩散Transformer弥合图像到视频的鸿沟实现高保真人脸替换
图生视频
扩散模型
Xu Guo, Fulong Ye, Xinghui Li, et al.
NextFlow:统一的序列建模激活多模态理解与生成
文生图
图像生成
Huichao Zhang, Liao Qu, Yiheng Liu, et al.
K-EXAONE 技术报告
LLM
文本生成
Eunbi Choi, Kibong Choi, Seokhee Hong, et al.
Hunger Game Debate:多智能体系统中过度竞争的涌现
Agent
LLM
Xinbei Ma, Ruotian Ma, Xingyu Chen, et al.
使用评分标准奖励训练AI协作者科学家
Agent
推理
Shashwat Goel, Rishi Hazra, Dulhan Jayalath, et al.
AdaGaR:面向动态场景重建的自适应Gabor表示
机器视觉 3D
深度估计
Jiewen Chan, Zhenjun Zhao, Yu-Lun Liu
驯服幻觉:通过反事实视频生成提升MLLMs的视频理解能力
扩散模型
视频理解
Zhe Huang, Hao Wen, Aiming Hao, et al.
SenseNova-MARS:通过强化学习赋能多模态智能体推理与搜索
Agent
多模态表征
Yong Xien Chng, Tao Hu, Wenwen Tong, et al.
Avatar Forcing:面向自然对话的实时交互式头部虚拟形象生成
人机交互
具身智能
Taekyung Ki, Sangwon Jang, Jaehyeong Jo, et al.
NeoVerse:利用真实场景单目视频增强4D世界模型
视频生成
3D 模型
Yuxue Yang, Lue Fan, Ziqi Shi, et al.
Youtu-Agent:基于自动化生成与混合策略优化的Agent生产率提升
Agent
LLM
Yuchen Shi, Yuzheng Cai, Siqi Cai, et al.
IQuest-Coder-V1 技术报告
代码生成
Agent
Jian Yang, Wei Zhang, Shawn Guo, et al.
递归语言模型
LLM
Agent
Alex L. Zhang, Tim Kraska, Omar Khattab
FlowBlending:面向快速高保真视频生成的阶段感知多模型采样
视频生成
扩散模型
Jibin Song, Mingi Kwon, Jaeseok Jeong, et al.
Dream2Flow:基于3D物体流连接视频生成与开放世界操控
视频生成
机器人技术
Karthik Dharmarajan, Wenlong Huang, Jiajun Wu, et al.
扩散LLM中的离散性作用
扩散模型
LLM
Ziqi Jin, Bin Wang, Xiang Lin, et al.
DiffThinker:面向生成式多模态推理的扩散模型
扩散模型
推理
Zefeng He, Xiaoye Qu, Yafu Li, et al.
动态大概念模型:自适应语义空间中的潜在推理
LLM
自然语言处理
Xingwei Qu, Shaowen Wang, Zihao Huang, et al.
基于超图记忆的多步RAG在长上下文复杂关系建模中的优化
检索增强生成
推理
Chulun Zhou, Chunkang Zhang, Guoxin Yu, et al.
人工智能与大脑的交汇:从认知神经科学到自主智能体的记忆系统
Agent
LLM
Jiafeng Liang, Hao Li, Chang Li, et al.
1
3
4
5
6
7
8
9
48