HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
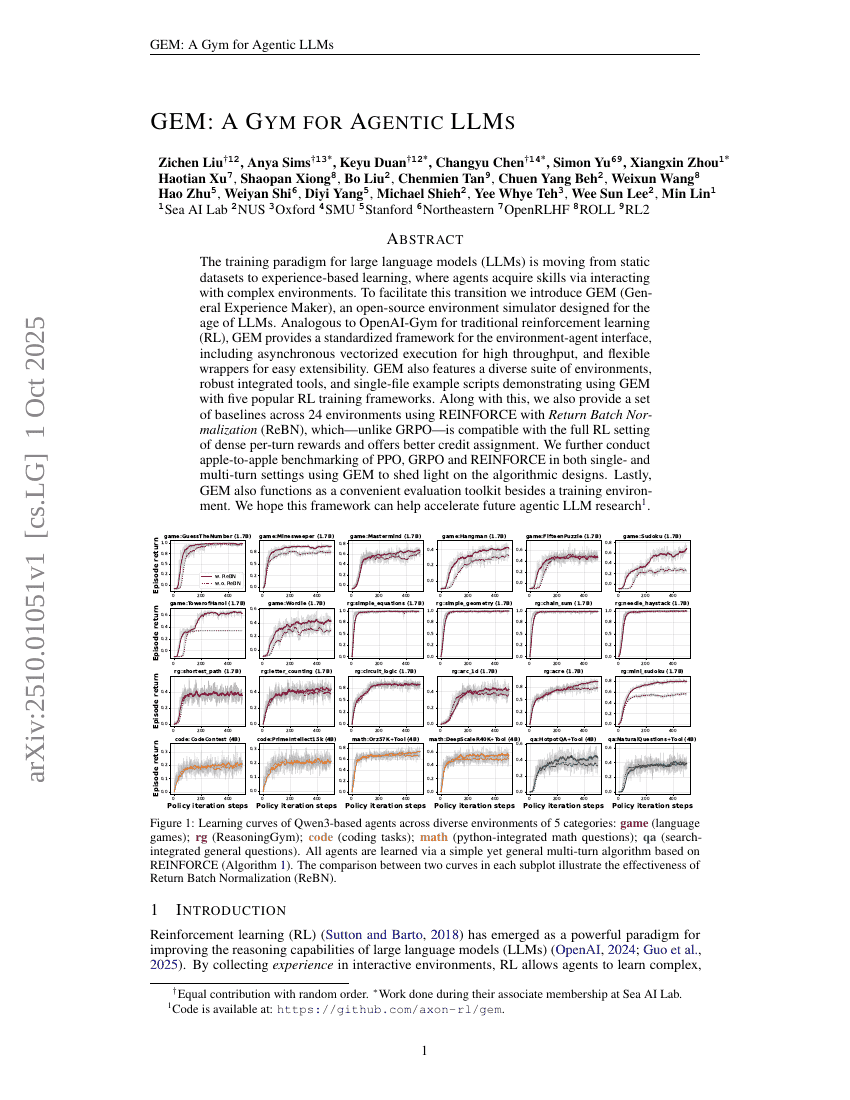
GEM:面向智能体LLM的健身房
LLM
强化学习
Zichen Liu, Anya Sims, Keyu Duan, et al.
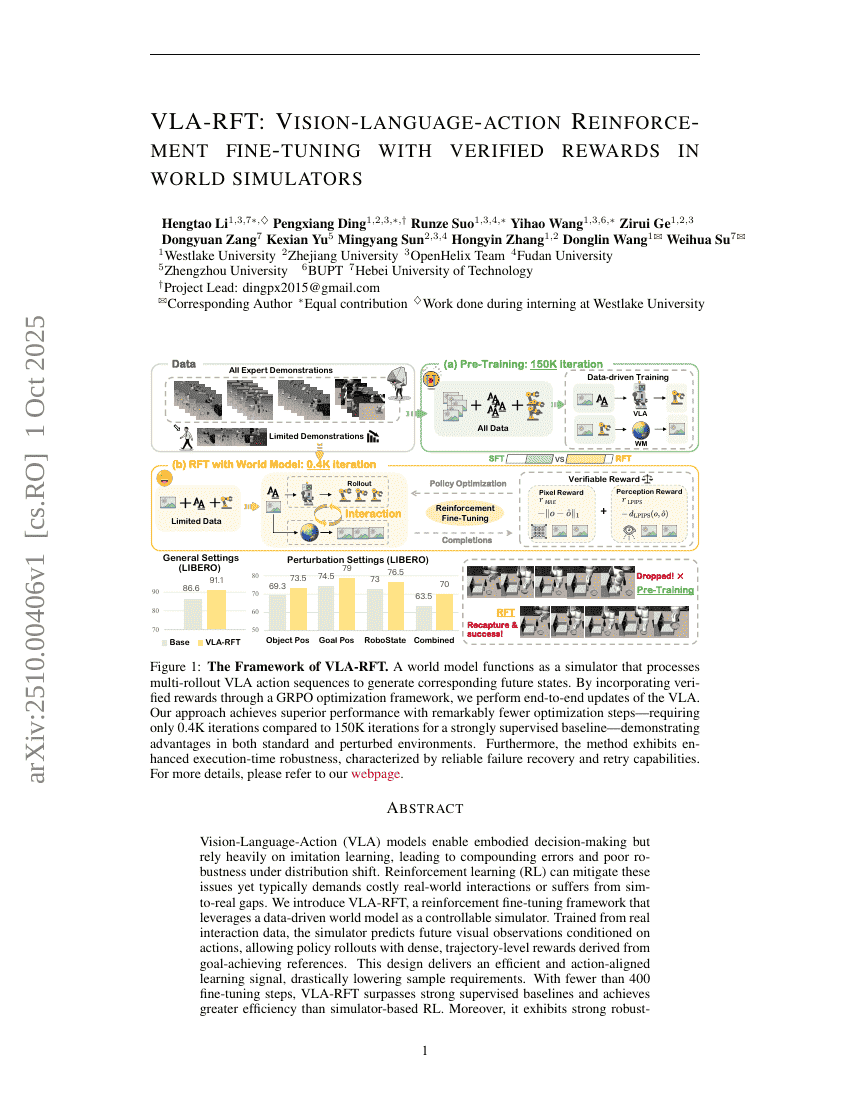
VLA-RFT:基于世界模拟器中验证奖励的视觉-语言-动作强化微调
强化学习
具身智能
Hengtao Li, Pengxiang Ding, Runze Suo, et al.
DeepSearch:通过蒙特卡洛树搜索克服强化学习中可验证奖励的瓶颈
强化学习
推理
Fang Wu, Weihao Xuan, Heli Qi, et al.
OceanGym:水下具身Agent的基准环境
具身智能
多模态
Yida Xue, Mingjun Mao, Xiangyuan Ru, et al.
TruthRL:通过强化学习激励LLM说真话
强化学习
监督式微调
Zhepei Wei, Xiao Yang, Kai Sun, et al.
赢得剪枝赌局:一种面向高效监督微调的联合样本与token剪枝统一方法
监督式微调
LLM
Shaobo Wang, Jiaming Wang, Jiajun Zhang, et al.
龙之幼崽:Transformer与大脑模型之间的缺失环节
Transformer
自然语言处理
Adrian Kosowski, Przemysław Uznański, Jan Chorowski, et al.
Vision-Zero:通过策略性游戏化自对弈实现可扩展的VLM自我提升
视觉问答
多模态
Qinsi Wang, Bo Liu, Tianyi Zhou, et al.
MCPMark:用于压力测试现实且全面的MCP使用的基准
基准
Agent
Zijian Wu, Xiangyan Liu, Xinyuan Zhang, et al.
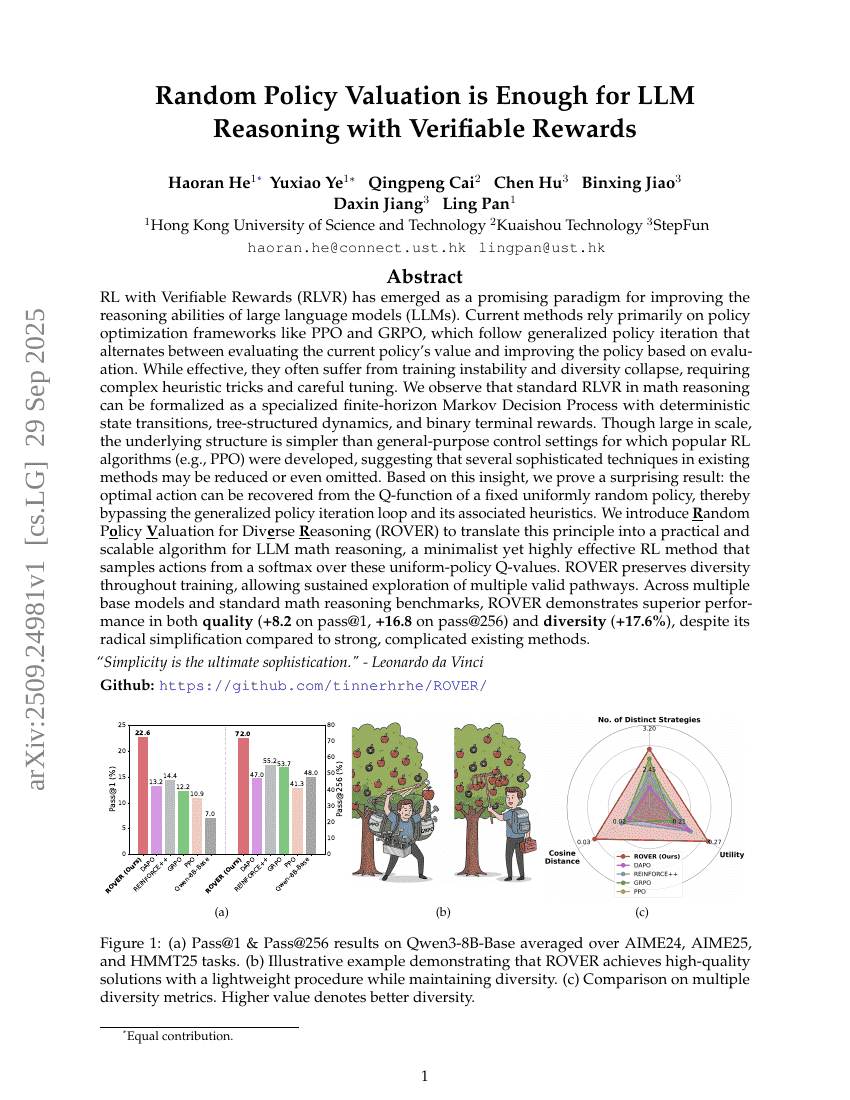
可验证奖励下的LLM推理仅需随机策略评估
强化学习
推理
Haoran He, Yuxiao Ye, Qingpeng Cai, et al.
使用ToolUniverse实现AI科学家的民主化
Agent
推理
Shanghua Gao, Richard Zhu, Pengwei Sui, et al.
推理何时才重要?一项关于推理对模型性能贡献的受控研究
推理
监督式微调
Nicolas Boizard, Hippolyte Gisserot-Boukhlef, Kevin El-Haddad, et al.
多人博弈纳什偏好优化
偏好
强化学习
Fang Wu, Xu Huang, Weihao Xuan, et al.
StableToken:一种抗噪声的语义语音Tokenize,用于增强语音LLM的鲁棒性
音频和语音处理
Transformer
Yuhan Song, Linhao Zhang, Chuhan Wu, et al.
SLA:通过可微调稀疏线性注意力实现扩散Transformer中的稀疏性突破
扩散模型
Transformer
Jintao Zhang, Haoxu Wang, Kai Jiang, et al.
SimpleFold:蛋白质折叠比你想象的更简单
Transformer
AI for Science
Yuyang Wang, Jiarui Lu, Navdeep Jaitly, et al.
POINTS-Reader:面向文档转换的视觉-语言模型蒸馏-free适配
文档理解
多模态
Yuan Liu, Zhongyin Zhao, Le Tian, et al.
可泛化的几何图像描述生成
图像描述
多模态
Yue Xin, Wenyuan Wang, Rui Pan, et al.
基于强化学习的语言模型规划:理论视角下的优势与陷阱
强化学习
监督式微调
Siwei Wang, Yifei Shen, Haoran Sun, et al.
语言模型Agent的赋能估计
LLM
Agent
Jinyeop Song, Jeff Gore, Max Kleiman-Weiner
语言模型可以在没有标量奖励的情况下从口头反馈中学习
LLM
强化学习
Renjie Luo, Zichen Liu, Xiangyan Liu, et al.
语言模型的变分推理
推理
LLM
Xiangxin Zhou, Zichen Liu, Haonan Wang, et al.
EPO:面向LLM Agent的熵正则化策略优化 强化学习
强化学习
LLM
Xu Wujiang, Wentian Zhao, Zhenting Wang, et al.
MinerU2.5:一种用于高效高分辨率文档解析的解耦视觉-语言模型
文档理解
多模态
Junbo Niu, Zheng Liu, Zhuangcheng Gu, et al.
分位数优势估计用于熵安全推理
强化学习
LLM
Junkang Wu, Kexin Huang, Jiancan Wu, et al.
LongLive:实时交互式长视频生成
视频生成
文生视频
Shuai Yang, Wei Huang, Ruihang Chu, et al.
组合式创造力:泛化能力的新前沿
LLM
算法
Samuel Schapiro, Sumuk Shashidhar, Alexi Gladstone, et al.
因果时空预测:一种高效且有效的多模态方法
多模态
统一多模态
Yuting Huang, Ziquan Fang, Zhihao Zeng, et al.
Hunyuan3D-Omni:一种用于可控生成3D资产的统一框架
3D 生成
多模态
Team Hunyuan3D, Bowen Zhang, Chunchao Guo, et al.
Seedream 4.0:迈向下一代多模态图像生成
文生图
扩散模型
Team Seedream, Yunpeng Chen, Yu Gao, et al.
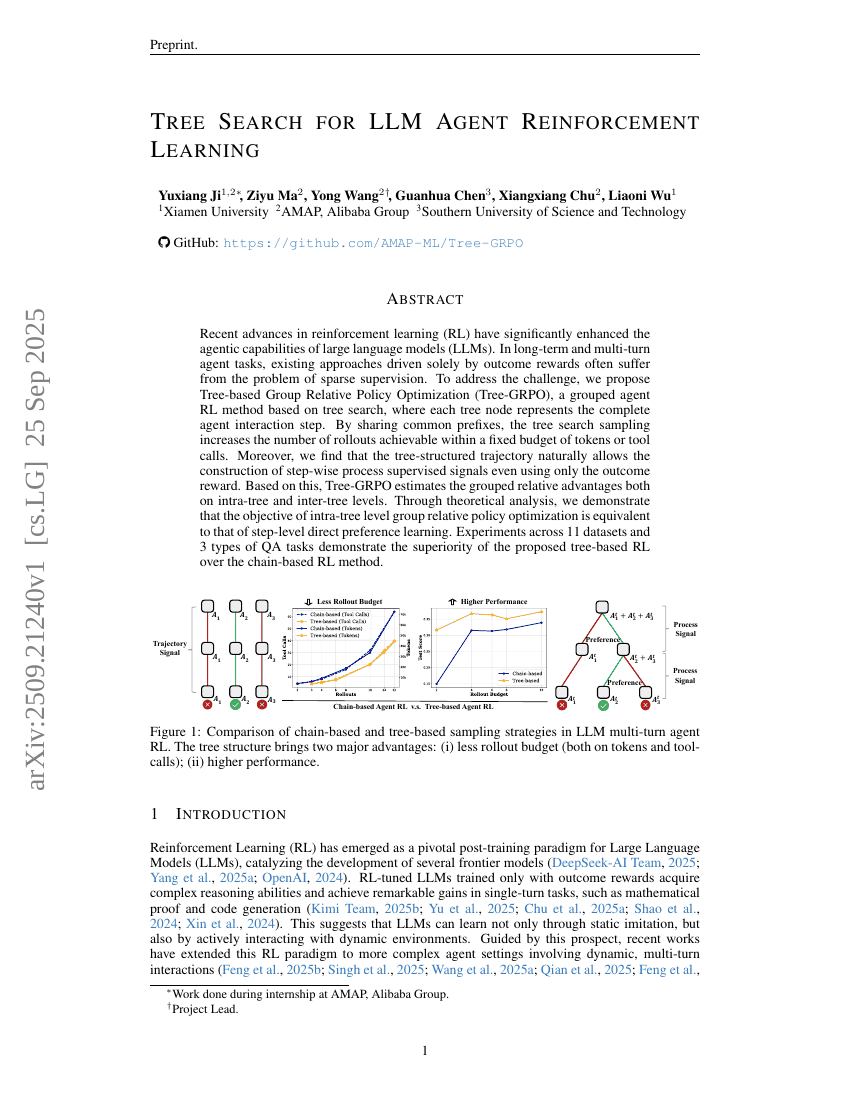
LLM Agent强化学习中的树搜索
强化学习
LLM
Yuxiang Ji, Ziyu Ma, Yong Wang, et al.
SciReasoner:跨学科奠定科学推理基础
推理
LLM
Yizhou Wang, Chen Tang, Han Deng, et al.
1
23
24
25
26
27
28
29
48
GEM:面向智能体LLM的健身房
LLM
强化学习
Zichen Liu, Anya Sims, Keyu Duan, et al.
VLA-RFT:基于世界模拟器中验证奖励的视觉-语言-动作强化微调
强化学习
具身智能
Hengtao Li, Pengxiang Ding, Runze Suo, et al.
DeepSearch:通过蒙特卡洛树搜索克服强化学习中可验证奖励的瓶颈
强化学习
推理
Fang Wu, Weihao Xuan, Heli Qi, et al.
OceanGym:水下具身Agent的基准环境
具身智能
多模态
Yida Xue, Mingjun Mao, Xiangyuan Ru, et al.
TruthRL:通过强化学习激励LLM说真话
强化学习
监督式微调
Zhepei Wei, Xiao Yang, Kai Sun, et al.
赢得剪枝赌局:一种面向高效监督微调的联合样本与token剪枝统一方法
监督式微调
LLM
Shaobo Wang, Jiaming Wang, Jiajun Zhang, et al.
龙之幼崽:Transformer与大脑模型之间的缺失环节
Transformer
自然语言处理
Adrian Kosowski, Przemysław Uznański, Jan Chorowski, et al.
Vision-Zero:通过策略性游戏化自对弈实现可扩展的VLM自我提升
视觉问答
多模态
Qinsi Wang, Bo Liu, Tianyi Zhou, et al.
MCPMark:用于压力测试现实且全面的MCP使用的基准
基准
Agent
Zijian Wu, Xiangyan Liu, Xinyuan Zhang, et al.
可验证奖励下的LLM推理仅需随机策略评估
强化学习
推理
Haoran He, Yuxiao Ye, Qingpeng Cai, et al.
使用ToolUniverse实现AI科学家的民主化
Agent
推理
Shanghua Gao, Richard Zhu, Pengwei Sui, et al.
推理何时才重要?一项关于推理对模型性能贡献的受控研究
推理
监督式微调
Nicolas Boizard, Hippolyte Gisserot-Boukhlef, Kevin El-Haddad, et al.
多人博弈纳什偏好优化
偏好
强化学习
Fang Wu, Xu Huang, Weihao Xuan, et al.
StableToken:一种抗噪声的语义语音Tokenize,用于增强语音LLM的鲁棒性
音频和语音处理
Transformer
Yuhan Song, Linhao Zhang, Chuhan Wu, et al.
SLA:通过可微调稀疏线性注意力实现扩散Transformer中的稀疏性突破
扩散模型
Transformer
Jintao Zhang, Haoxu Wang, Kai Jiang, et al.
SimpleFold:蛋白质折叠比你想象的更简单
Transformer
AI for Science
Yuyang Wang, Jiarui Lu, Navdeep Jaitly, et al.
POINTS-Reader:面向文档转换的视觉-语言模型蒸馏-free适配
文档理解
多模态
Yuan Liu, Zhongyin Zhao, Le Tian, et al.
可泛化的几何图像描述生成
图像描述
多模态
Yue Xin, Wenyuan Wang, Rui Pan, et al.
基于强化学习的语言模型规划:理论视角下的优势与陷阱
强化学习
监督式微调
Siwei Wang, Yifei Shen, Haoran Sun, et al.
语言模型Agent的赋能估计
LLM
Agent
Jinyeop Song, Jeff Gore, Max Kleiman-Weiner
语言模型可以在没有标量奖励的情况下从口头反馈中学习
LLM
强化学习
Renjie Luo, Zichen Liu, Xiangyan Liu, et al.
语言模型的变分推理
推理
LLM
Xiangxin Zhou, Zichen Liu, Haonan Wang, et al.
EPO:面向LLM Agent的熵正则化策略优化 强化学习
强化学习
LLM
Xu Wujiang, Wentian Zhao, Zhenting Wang, et al.
MinerU2.5:一种用于高效高分辨率文档解析的解耦视觉-语言模型
文档理解
多模态
Junbo Niu, Zheng Liu, Zhuangcheng Gu, et al.
分位数优势估计用于熵安全推理
强化学习
LLM
Junkang Wu, Kexin Huang, Jiancan Wu, et al.
LongLive:实时交互式长视频生成
视频生成
文生视频
Shuai Yang, Wei Huang, Ruihang Chu, et al.
组合式创造力:泛化能力的新前沿
LLM
算法
Samuel Schapiro, Sumuk Shashidhar, Alexi Gladstone, et al.
因果时空预测:一种高效且有效的多模态方法
多模态
统一多模态
Yuting Huang, Ziquan Fang, Zhihao Zeng, et al.
Hunyuan3D-Omni:一种用于可控生成3D资产的统一框架
3D 生成
多模态
Team Hunyuan3D, Bowen Zhang, Chunchao Guo, et al.
Seedream 4.0:迈向下一代多模态图像生成
文生图
扩散模型
Team Seedream, Yunpeng Chen, Yu Gao, et al.
LLM Agent强化学习中的树搜索
强化学习
LLM
Yuxiang Ji, Ziyu Ma, Yong Wang, et al.
SciReasoner:跨学科奠定科学推理基础
推理
LLM
Yizhou Wang, Chen Tang, Han Deng, et al.
1
23
24
25
26
27
28
29
48