HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
MMR1:通过方差感知采样与开放资源增强多模态推理
多模态
推理
Sicong Leng, Jing Wang, Jiaxi Li, et al.
基于方差的课程强化学习用于大语言模型
强化学习
LLM
Guochao Jiang, Wenfeng Feng, Guofeng Quan, et al.
MultiEdit:在多样且具有挑战性的任务上推进基于指令的图像编辑
图生图
多模态
Mingsong Li, Lin Liu, Hongjun Wang, et al.
BRISC:基于Swin-HAFNet的脑肿瘤分割与分类标注数据集
语义分割
图像分类
Amirreza Fateh, Yasin Rezvani, Sara Moayedi, et al.
FDABench:面向异构数据上分析查询的数据Agent基准测试
基准
Agent
Ziting Wang, Shize Zhang, Haitao Yuan, et al.
作画易,思辨难:文本到图像模型能否铺就舞台,却无法主导演出?
文生图
推理
Ouxiang Li, Yuan Wang, Xinting Hu, et al.
UniVerse-1:通过专家拼接实现统一的音视频生成
统一多模态
视频生成
Duomin Wang, Wei Zuo, Aojie Li, et al.
基础模型在逐步具身推理中的表现如何?
具身智能
基准
Dinura Dissanayake, Ahmed Heakl, Omkar Thawakar, et al.
脉冲脑技术报告:脉冲脑启发的大规模模型
LLM
Transformer
Yuqi Pan, Yupeng Feng, Jinghao Zhuang, et al.
SAGE:语义理解的现实基准
基准
数据集
Samarth Goel, Reagan J. Lee, Kannan Ramchandran
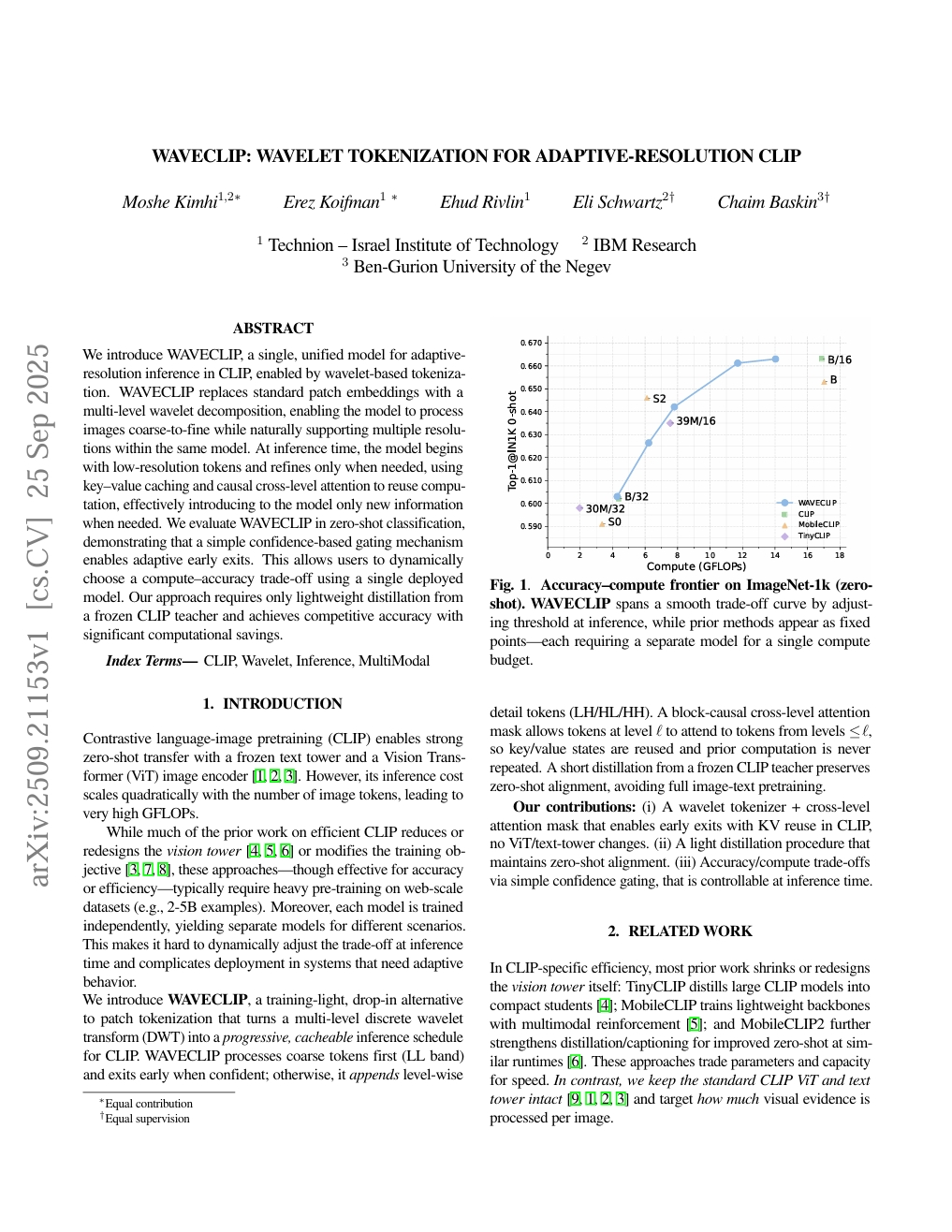
WAVECLIP:小波Token化用于自适应分辨率CLIP
Transformer
图像分类
Moshe Kimhi, Erez Koifman, Ehud Rivlin, et al.
EmbeddingGemma:强大且轻量的文本表示
LLM
Transformer
Henrique Schechter Vera, Sahil Dua, Biao Zhang, et al.
通过GRPO提升语音感知语言模型中的语音理解能力
LLM
监督式微调
Avishai Elmakies, Hagai Aronowitz, Nimrod Shabtay, et al.
VLMs 距离视觉空间智能还有多远?一项基准驱动的视角
基准
多模态
Songsong Yu, Yuxin Chen, Hao Ju, et al.
SIM-CoT:监督式隐式思维链
LLM
监督式微调
Xilin Wei, Xiaoran Liu, Yuhang Zang, et al.
SWE-QA:语言模型能否回答仓库级代码问题?
智能问答
基准
Weihan Peng, Yuling Shi, Yuhang Wang, et al.
视频模型是零样本学习者和推理者
视频理解
多模态
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, et al.
用于机械工程分析问题关键求解的N-Plus-1 GPT Agent
LLM
建模
Anthony Patera, Rohan Abeyaratne
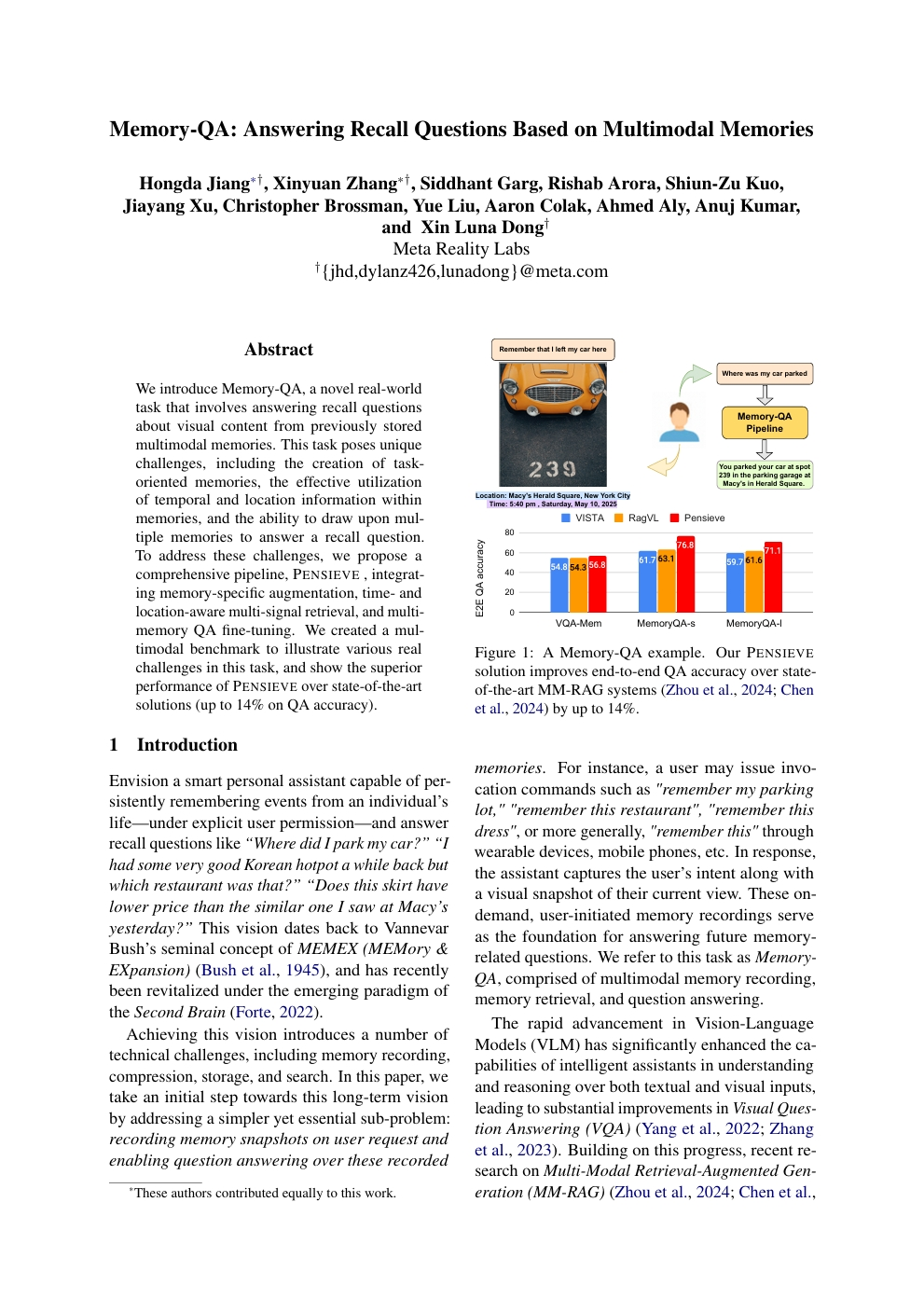
Memory-QA:基于多模态记忆的回忆问答
视觉问答
检索增强生成
Hongda Jiang, Xinyuan Zhang, Siddhant Garg, et al.
MAPO:混合优势策略优化
强化学习
偏好
Wenke Huang, Quan Zhang, Yiyang Fang, et al.
Hyper-Bagel:一种用于多模态理解与生成的统一加速框架
统一多模态
扩散模型
Yanzuo Lu, Xin Xia, Manlin Zhang, et al.
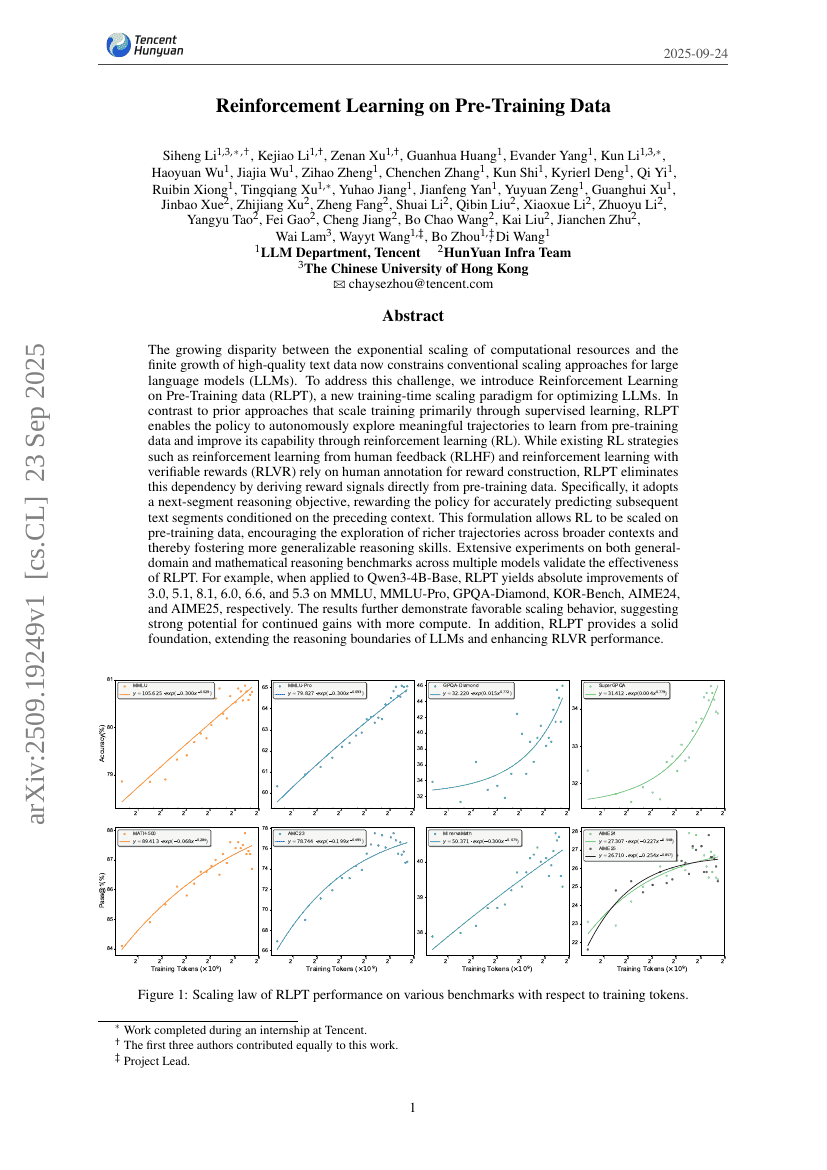
预训练数据上的强化学习
强化学习
LLM
Siheng Li, Kejiao Li, Zenan Xu, et al.
视觉运动策略中是否需要本体感觉状态?
机器人技术
具身智能
Juntu Zhao, Wenbo Lu, Di Zhang, et al.
Baseer:用于阿拉伯文文档到Markdown OCR的视觉-语言模型
OCR
LLM
Khalil Hennara, Muhammad Hreden, Mohamed Motasim Hamed, et al.
GenExam:跨学科文本到图像测评
文生图
图像生成
Zhaokai Wang, Penghao Yin, Xiangyu Zhao, et al.
Nav-R1:具身场景中的推理与导航
具身智能
强化学习
Qingxiang Liu, Ting Huang, Zeyu Zhang, et al.
MoEs 比你想象的更强大:基于 RoE 的超并行推理扩展
LLM
Transformer
Soheil Zibakhsh, Mohammad Samragh, Kumari Nishu, et al.
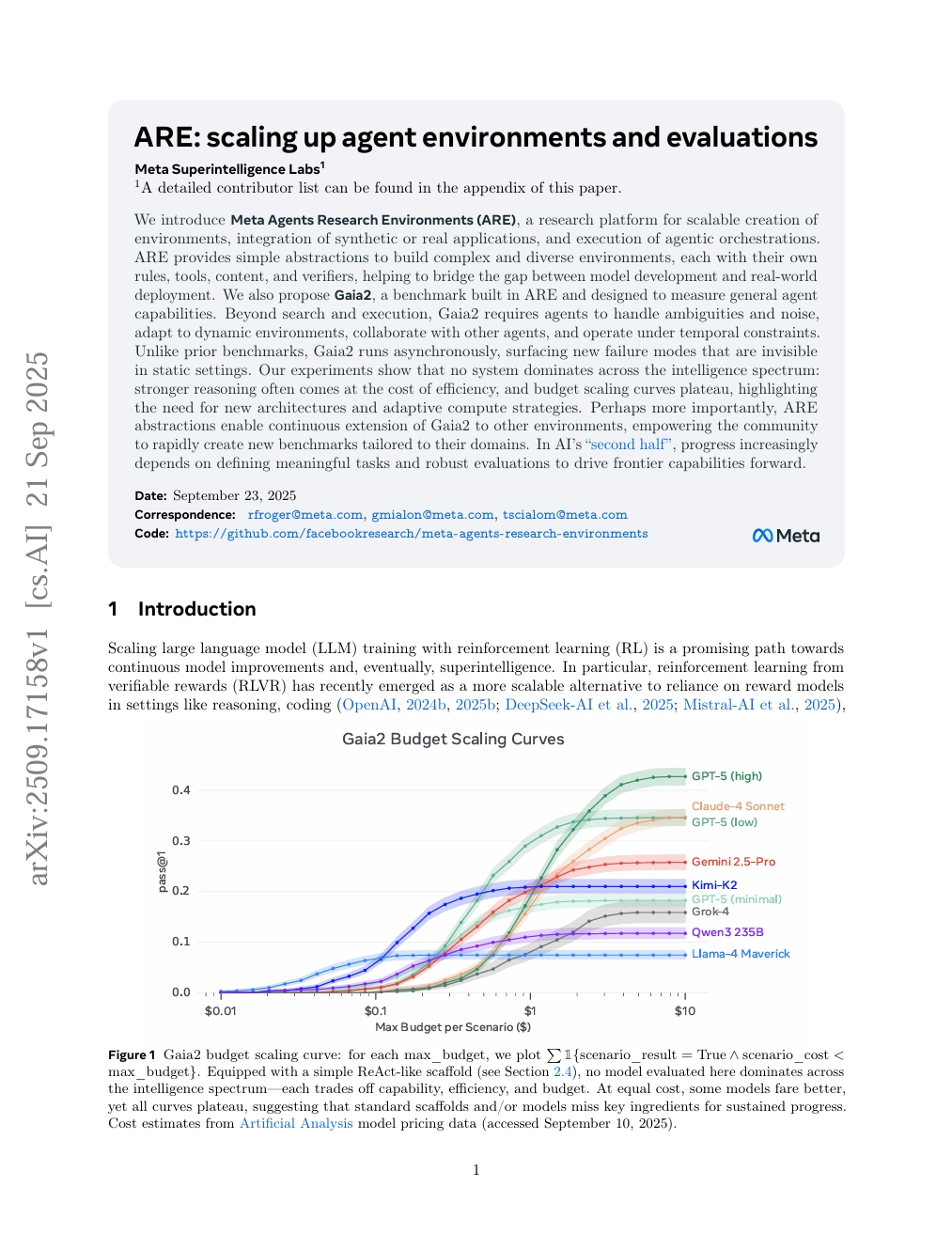
ARE:扩展Agent环境与评估
Agent
基准
Pierre Andrews, Amine Benhalloum, Gerard Moreno-Torres Bertran, et al.
DiffusionNFT:基于前向过程的在线扩散强化
扩散模型
强化学习
Kaiwen Zheng, Huayu Chen, Haotian Ye, et al.
TempSamp-R1:面向视频LLM的强化微调有效时间采样
强化学习
LLM
Yunheng Li, Jing Cheng, Shaoyong Jia, et al.
OnePiece:将上下文工程与推理引入工业级级联排序系统
LLM
多任务学习
Sunhao Dai, Jiakai Tang, Jiahua Wu, et al.
OmniInsert:通过扩散Transformer模型实现无掩码的任意参考视频插入
视频生成
图生视频
Jinshu Chen, Xinghui Li, Xu Bai, et al.
1
24
25
26
27
28
29
30
48
MMR1:通过方差感知采样与开放资源增强多模态推理
多模态
推理
Sicong Leng, Jing Wang, Jiaxi Li, et al.
基于方差的课程强化学习用于大语言模型
强化学习
LLM
Guochao Jiang, Wenfeng Feng, Guofeng Quan, et al.
MultiEdit:在多样且具有挑战性的任务上推进基于指令的图像编辑
图生图
多模态
Mingsong Li, Lin Liu, Hongjun Wang, et al.
BRISC:基于Swin-HAFNet的脑肿瘤分割与分类标注数据集
语义分割
图像分类
Amirreza Fateh, Yasin Rezvani, Sara Moayedi, et al.
FDABench:面向异构数据上分析查询的数据Agent基准测试
基准
Agent
Ziting Wang, Shize Zhang, Haitao Yuan, et al.
作画易,思辨难:文本到图像模型能否铺就舞台,却无法主导演出?
文生图
推理
Ouxiang Li, Yuan Wang, Xinting Hu, et al.
UniVerse-1:通过专家拼接实现统一的音视频生成
统一多模态
视频生成
Duomin Wang, Wei Zuo, Aojie Li, et al.
基础模型在逐步具身推理中的表现如何?
具身智能
基准
Dinura Dissanayake, Ahmed Heakl, Omkar Thawakar, et al.
脉冲脑技术报告:脉冲脑启发的大规模模型
LLM
Transformer
Yuqi Pan, Yupeng Feng, Jinghao Zhuang, et al.
SAGE:语义理解的现实基准
基准
数据集
Samarth Goel, Reagan J. Lee, Kannan Ramchandran
WAVECLIP:小波Token化用于自适应分辨率CLIP
Transformer
图像分类
Moshe Kimhi, Erez Koifman, Ehud Rivlin, et al.
EmbeddingGemma:强大且轻量的文本表示
LLM
Transformer
Henrique Schechter Vera, Sahil Dua, Biao Zhang, et al.
通过GRPO提升语音感知语言模型中的语音理解能力
LLM
监督式微调
Avishai Elmakies, Hagai Aronowitz, Nimrod Shabtay, et al.
VLMs 距离视觉空间智能还有多远?一项基准驱动的视角
基准
多模态
Songsong Yu, Yuxin Chen, Hao Ju, et al.
SIM-CoT:监督式隐式思维链
LLM
监督式微调
Xilin Wei, Xiaoran Liu, Yuhang Zang, et al.
SWE-QA:语言模型能否回答仓库级代码问题?
智能问答
基准
Weihan Peng, Yuling Shi, Yuhang Wang, et al.
视频模型是零样本学习者和推理者
视频理解
多模态
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, et al.
用于机械工程分析问题关键求解的N-Plus-1 GPT Agent
LLM
建模
Anthony Patera, Rohan Abeyaratne
Memory-QA:基于多模态记忆的回忆问答
视觉问答
检索增强生成
Hongda Jiang, Xinyuan Zhang, Siddhant Garg, et al.
MAPO:混合优势策略优化
强化学习
偏好
Wenke Huang, Quan Zhang, Yiyang Fang, et al.
Hyper-Bagel:一种用于多模态理解与生成的统一加速框架
统一多模态
扩散模型
Yanzuo Lu, Xin Xia, Manlin Zhang, et al.
预训练数据上的强化学习
强化学习
LLM
Siheng Li, Kejiao Li, Zenan Xu, et al.
视觉运动策略中是否需要本体感觉状态?
机器人技术
具身智能
Juntu Zhao, Wenbo Lu, Di Zhang, et al.
Baseer:用于阿拉伯文文档到Markdown OCR的视觉-语言模型
OCR
LLM
Khalil Hennara, Muhammad Hreden, Mohamed Motasim Hamed, et al.
GenExam:跨学科文本到图像测评
文生图
图像生成
Zhaokai Wang, Penghao Yin, Xiangyu Zhao, et al.
Nav-R1:具身场景中的推理与导航
具身智能
强化学习
Qingxiang Liu, Ting Huang, Zeyu Zhang, et al.
MoEs 比你想象的更强大:基于 RoE 的超并行推理扩展
LLM
Transformer
Soheil Zibakhsh, Mohammad Samragh, Kumari Nishu, et al.
ARE:扩展Agent环境与评估
Agent
基准
Pierre Andrews, Amine Benhalloum, Gerard Moreno-Torres Bertran, et al.
DiffusionNFT:基于前向过程的在线扩散强化
扩散模型
强化学习
Kaiwen Zheng, Huayu Chen, Haotian Ye, et al.
TempSamp-R1:面向视频LLM的强化微调有效时间采样
强化学习
LLM
Yunheng Li, Jing Cheng, Shaoyong Jia, et al.
OnePiece:将上下文工程与推理引入工业级级联排序系统
LLM
多任务学习
Sunhao Dai, Jiakai Tang, Jiahua Wu, et al.
OmniInsert:通过扩散Transformer模型实现无掩码的任意参考视频插入
视频生成
图生视频
Jinshu Chen, Xinghui Li, Xu Bai, et al.
1
24
25
26
27
28
29
30
48