HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Motion Attribution for Video Generation

VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory























Motion Attribution for Video Generation
VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
Ministral 3
The Confidence Dichotomy: Analyzing and Mitigating Miscalibration in Tool-Use Agents
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
ShowUI-π: Flow-based Generative Models as GUI Dexterous Hands
Learning Latent Action World Models In The Wild
Dr. Zero: Self-Evolving Search Agents without Training Data
MHLA: Restoring Expressivity of Linear Attention via Token-Level Multi-Head
GlimpRouter: Efficient Collaborative Inference by Glimpsing One Token of Thoughts
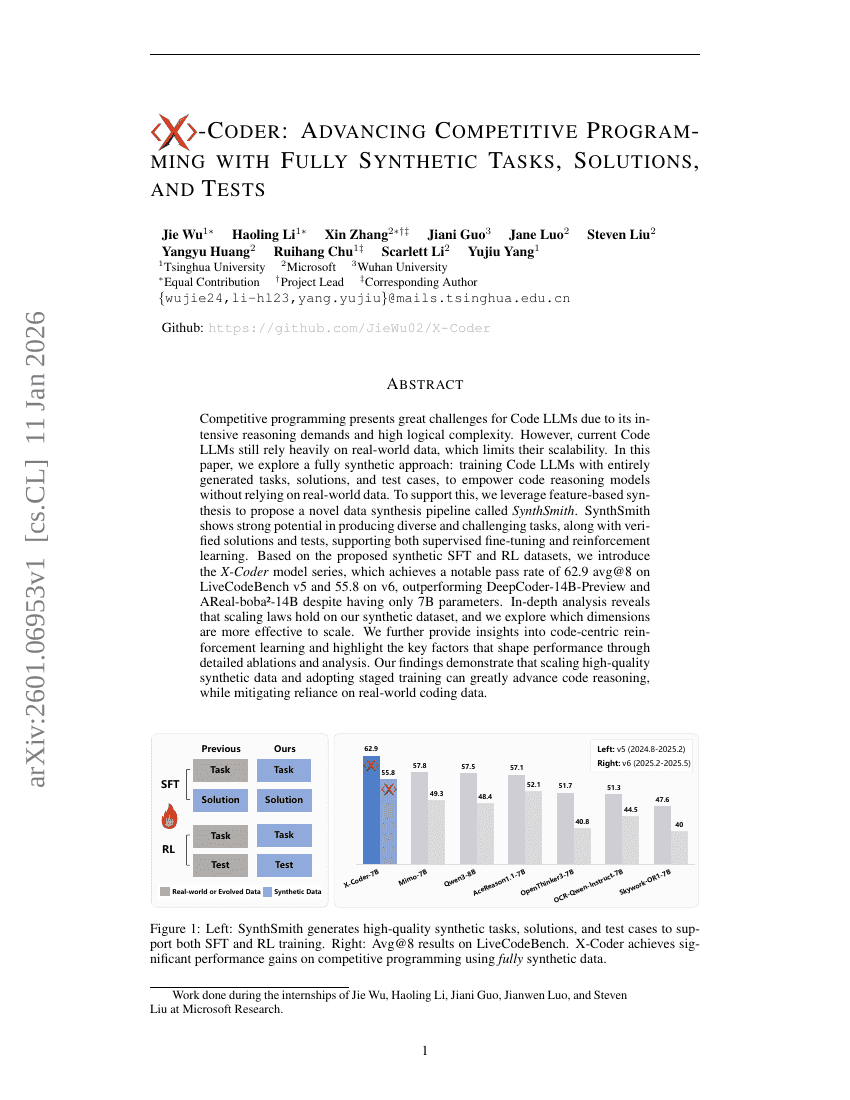
X-Coder: Advancing Competitive Programming with Fully Synthetic Tasks, Solutions, and Tests
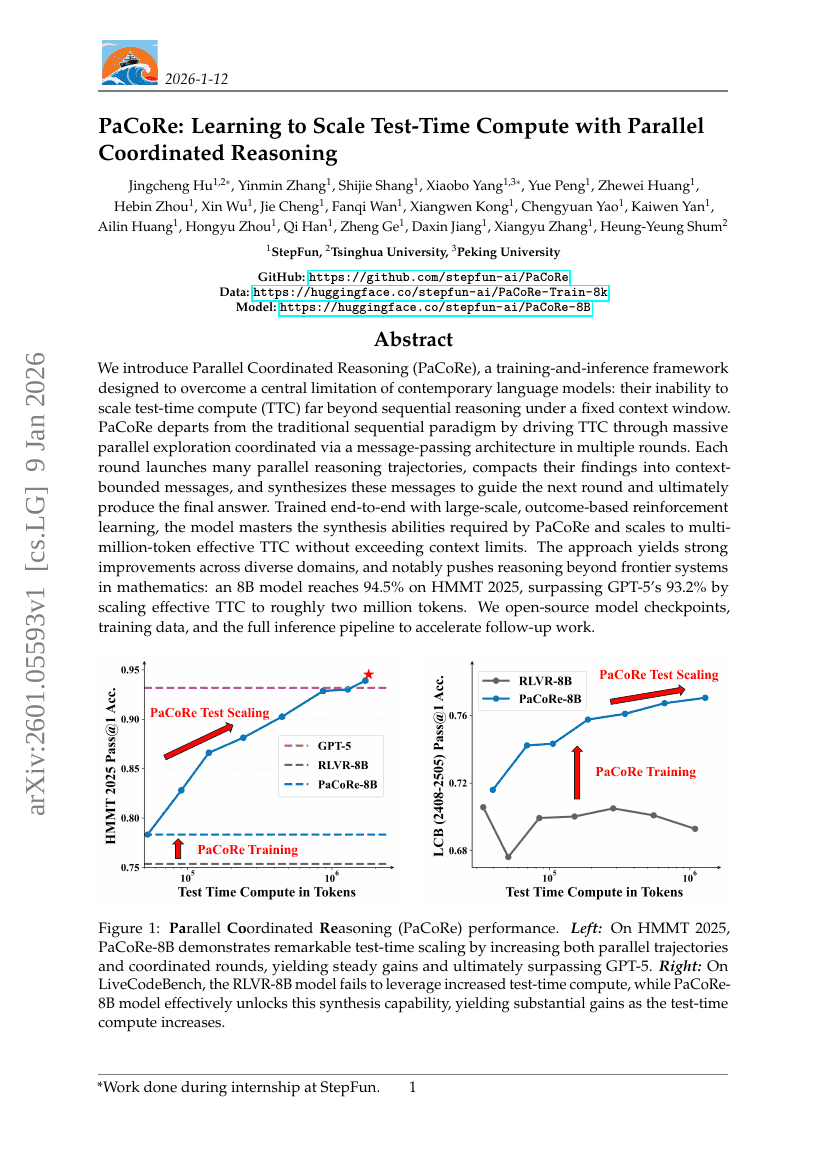
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
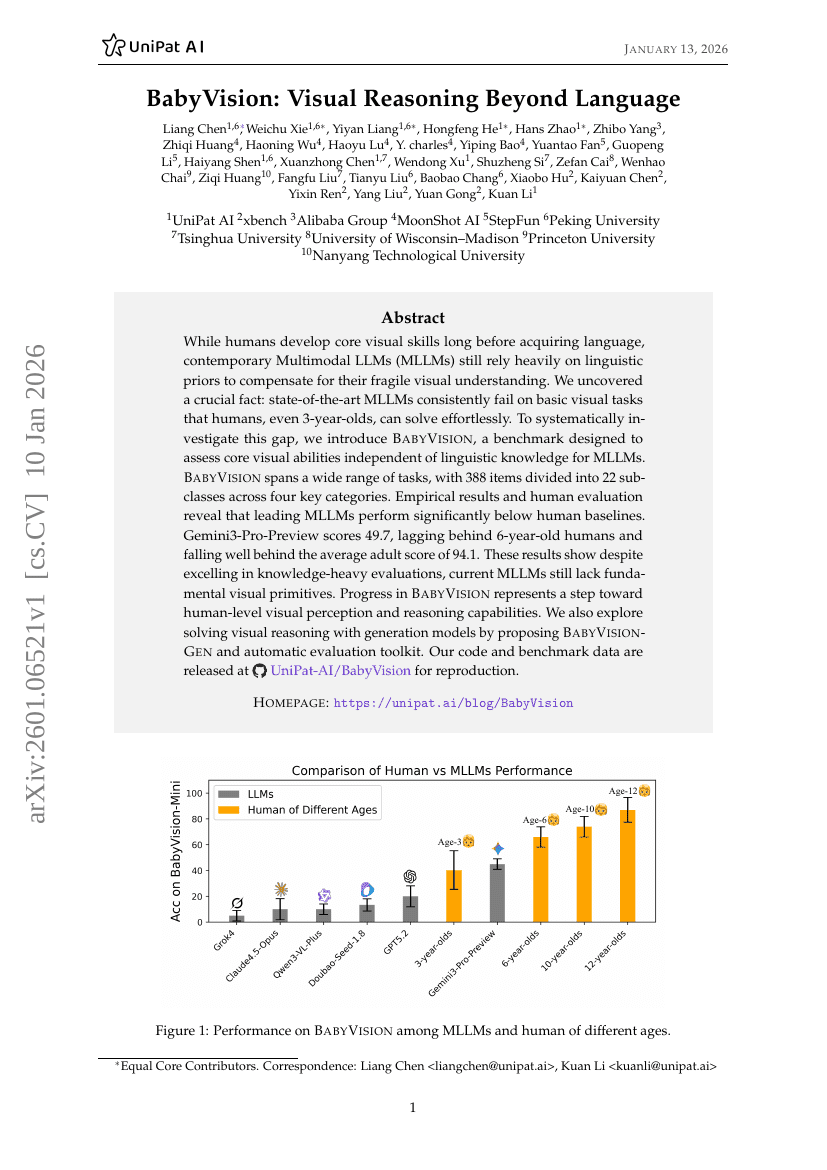
BabyVision: Visual Reasoning Beyond Language
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models
EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis
Chaining the Evidence: Robust Reinforcement Learning for Deep Search Agents with Citation-Aware Rubric Rewards
CaricatureGS: Exaggerating 3D Gaussian Splatting Faces With Gaussian Curvature
The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning
MMFormalizer: Multimodal Autoformalization in the Wild
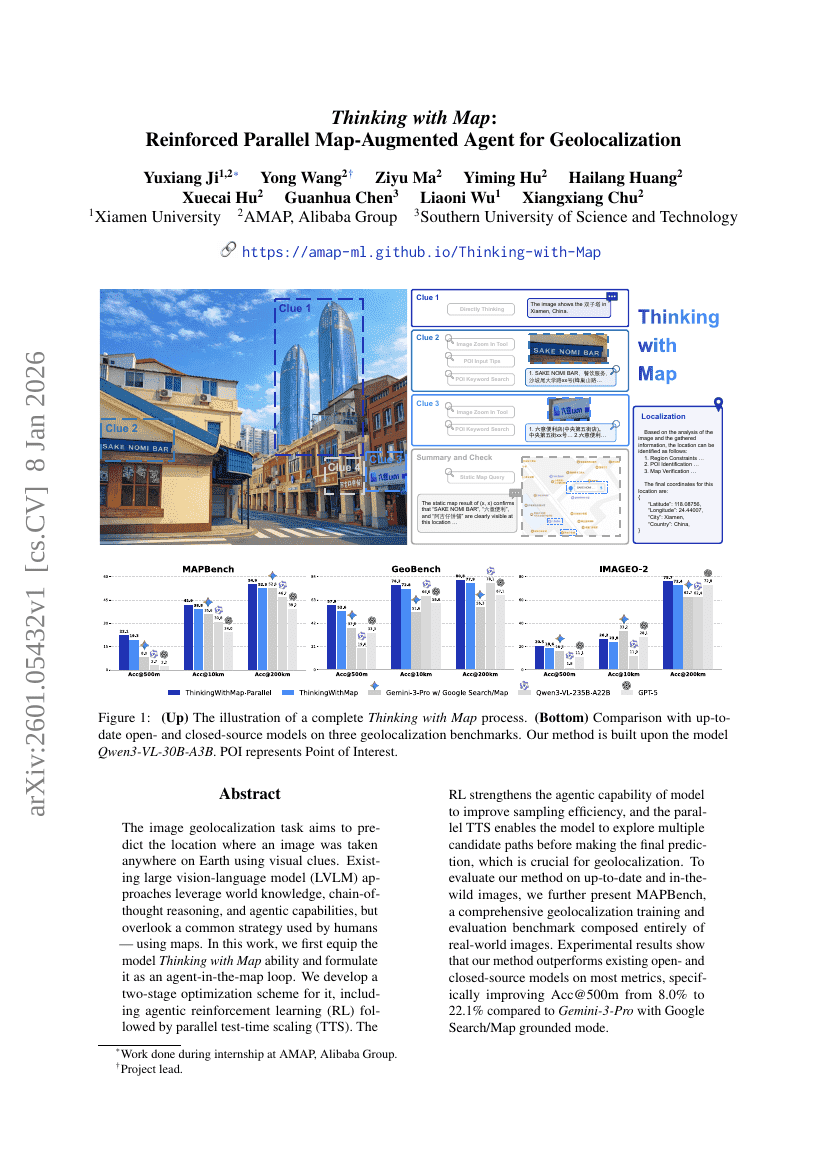
Thinking with Map: Reinforced Parallel Map-Augmented Agent for Geolocalization
Breaking the Sorting Barrier for Directed Single-Source Shortest Paths
GR-Dexter Technical Report
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
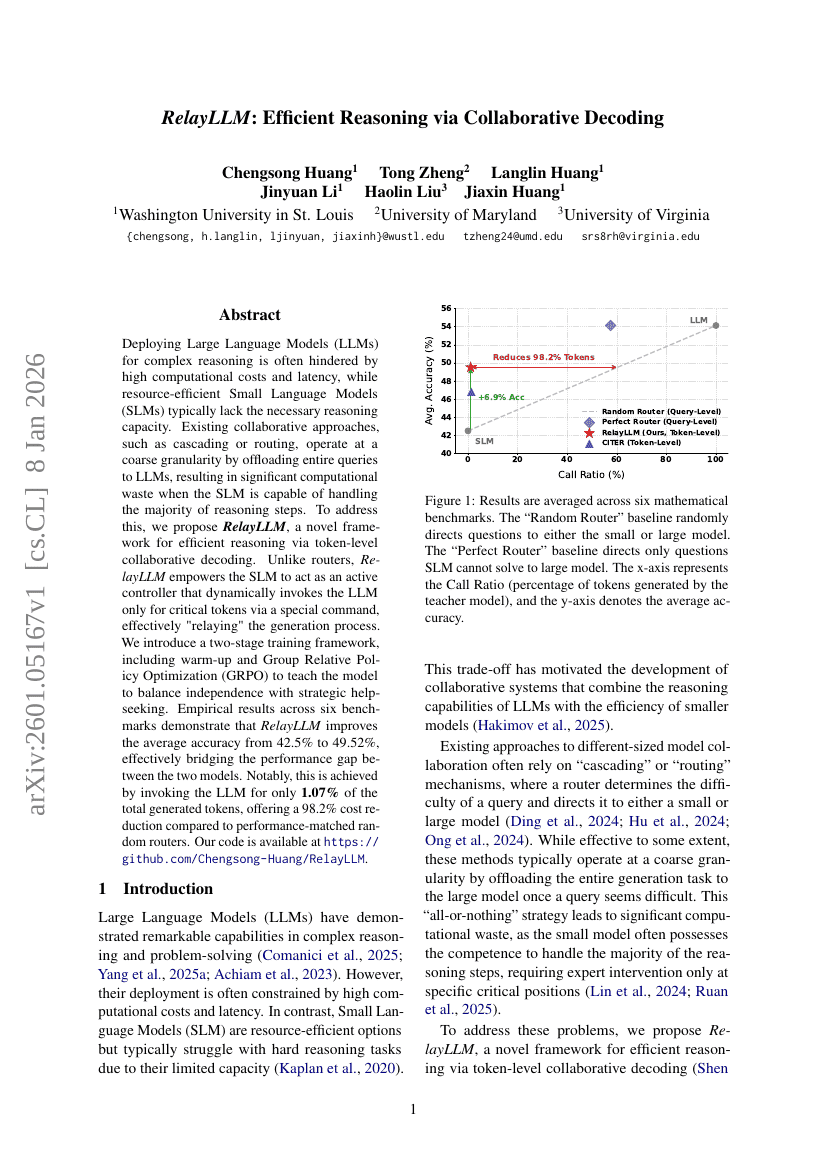
RelayLLM: Efficient Reasoning via Collaborative Decoding
Token-Level LLM Collaboration via FusionRoute
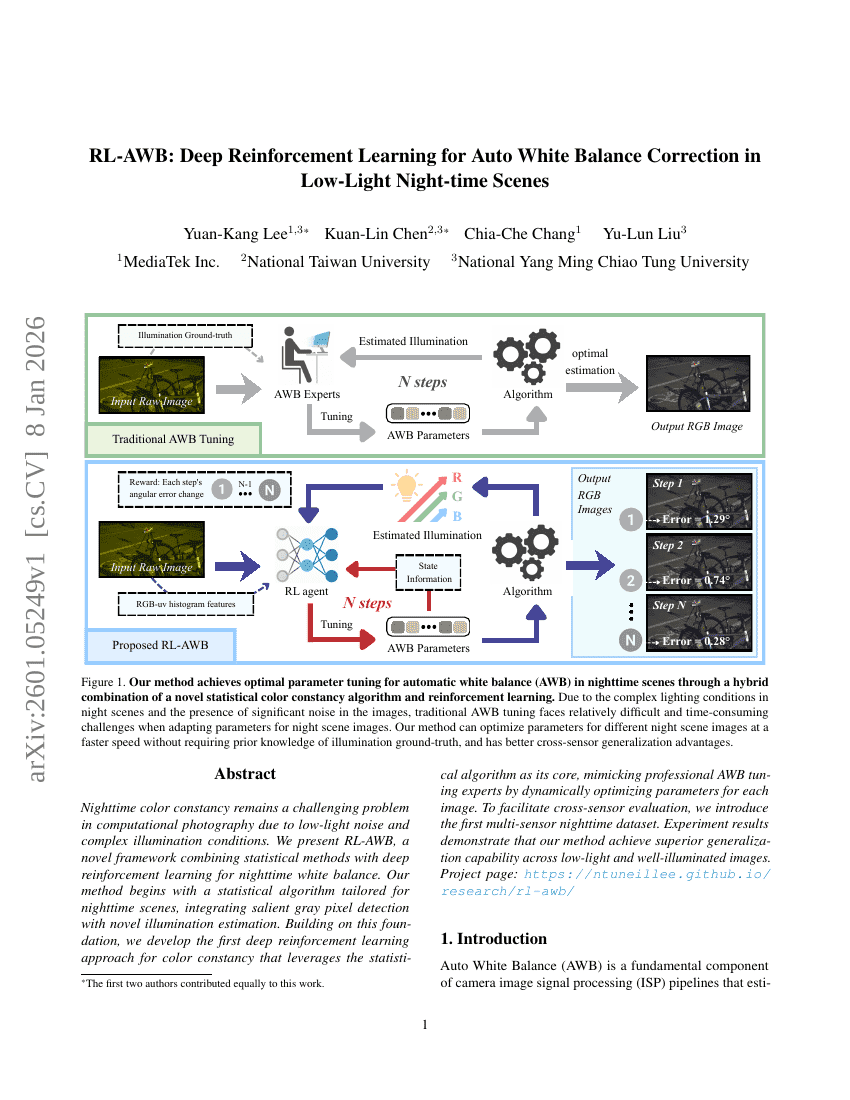
RL-AWB: Deep Reinforcement Learning for Auto White Balance Correction in Low-Light Night-time Scenes
Learnable Multipliers: Freeing the Scale of Language Model Matrix Layers
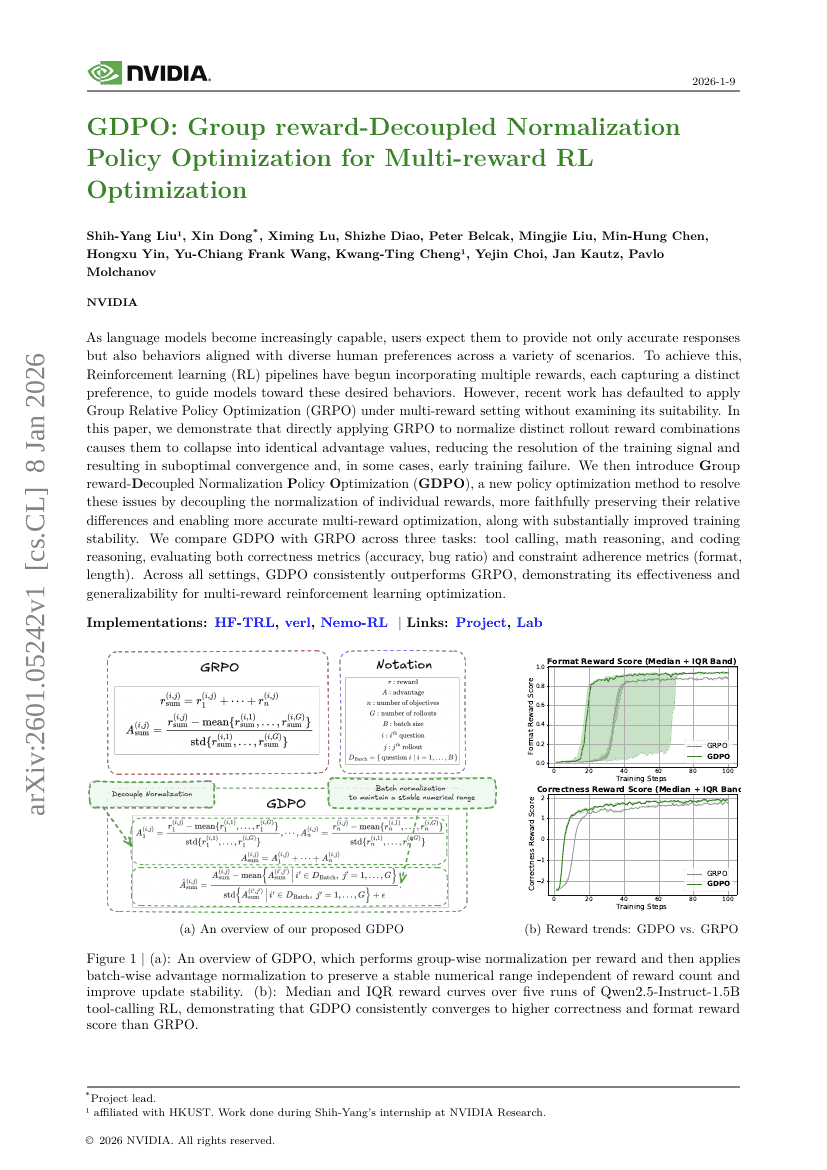
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
From Failure to Mastery: Generating Hard Samples for Tool-use Agents
Choreographing a World of Dynamic Objects
Ministral 3
The Confidence Dichotomy: Analyzing and Mitigating Miscalibration in Tool-Use Agents
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
ShowUI-π: Flow-based Generative Models as GUI Dexterous Hands
Learning Latent Action World Models In The Wild
Dr. Zero: Self-Evolving Search Agents without Training Data
MHLA: Restoring Expressivity of Linear Attention via Token-Level Multi-Head
GlimpRouter: Efficient Collaborative Inference by Glimpsing One Token of Thoughts
X-Coder: Advancing Competitive Programming with Fully Synthetic Tasks, Solutions, and Tests
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
BabyVision: Visual Reasoning Beyond Language
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models
EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis
Chaining the Evidence: Robust Reinforcement Learning for Deep Search Agents with Citation-Aware Rubric Rewards
CaricatureGS: Exaggerating 3D Gaussian Splatting Faces With Gaussian Curvature
The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning
MMFormalizer: Multimodal Autoformalization in the Wild
Thinking with Map: Reinforced Parallel Map-Augmented Agent for Geolocalization
Breaking the Sorting Barrier for Directed Single-Source Shortest Paths
GR-Dexter Technical Report
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
RelayLLM: Efficient Reasoning via Collaborative Decoding
Token-Level LLM Collaboration via FusionRoute
RL-AWB: Deep Reinforcement Learning for Auto White Balance Correction in Low-Light Night-time Scenes
Learnable Multipliers: Freeing the Scale of Language Model Matrix Layers
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
From Failure to Mastery: Generating Hard Samples for Tool-use Agents
Choreographing a World of Dynamic Objects