HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends
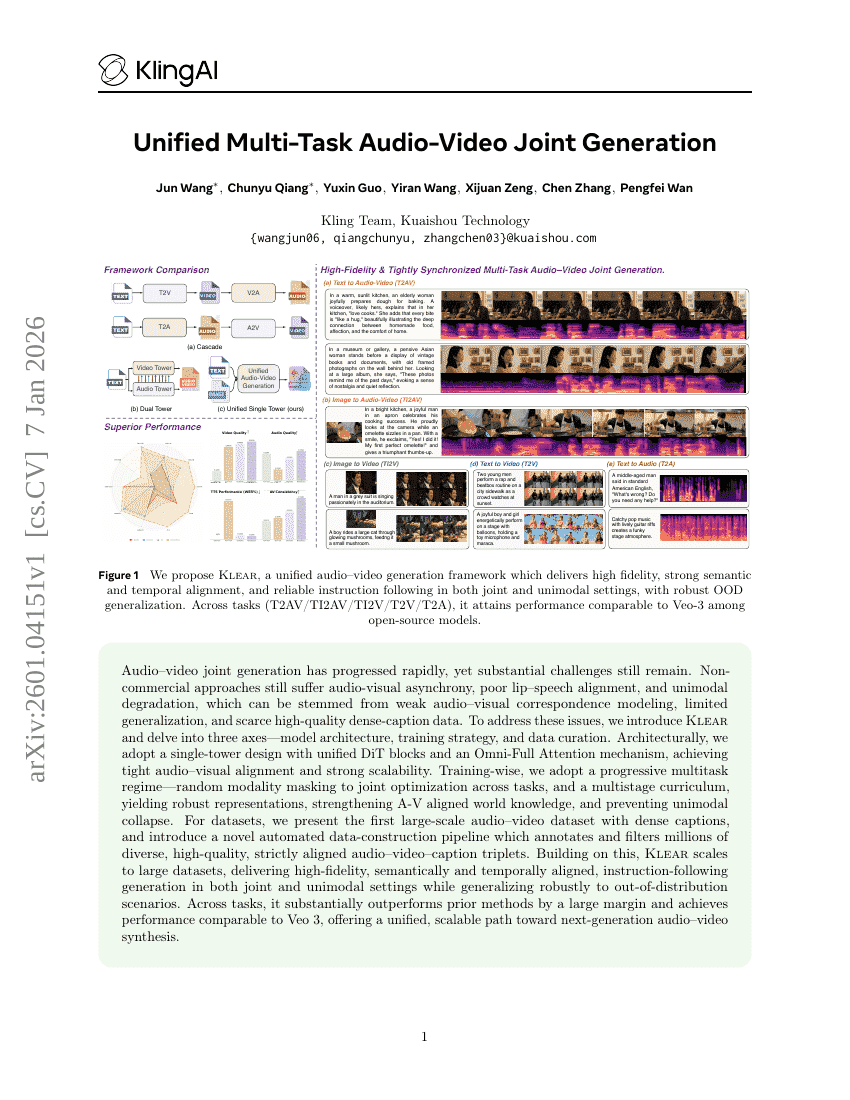
Klear: Unified Multi-Task Audio-Video Joint Generation

Atlas: Orchestrating Heterogeneous Models and Tools for Multi-Domain Complex Reasoning




























Klear: Unified Multi-Task Audio-Video Joint Generation
Atlas: Orchestrating Heterogeneous Models and Tools for Multi-Domain Complex Reasoning
Benchmark^2: Systematic Evaluation of LLM Benchmarks
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Entropy-Adaptive Fine-Tuning: Resolving Confident Conflicts to Mitigate Forgetting
Diversity or Precision? A Deep Dive into Next Token Prediction
Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
DreamStyle: A Unified Framework for Video Stylization
UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision
LTX-2: Efficient Joint Audio-Visual Foundation Model
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
MOSS Transcribe Diarize: Accurate Transcription with Speaker Diarization
InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
Adaptation of Agentic AI
Large Video Planner Enables Generalizable Robot Control
InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
GARDO: Reinforcing Diffusion Models without Reward Hacking
VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
K-EXAONE Technical Report
The Hunger Game Debate: On the Emergence of Over-Competition in Multi-Agent Systems
Training AI Co-Scientists Using Rubric Rewards
AdaGaR: Adaptive Gabor Representation for Dynamic Scene Reconstruction
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
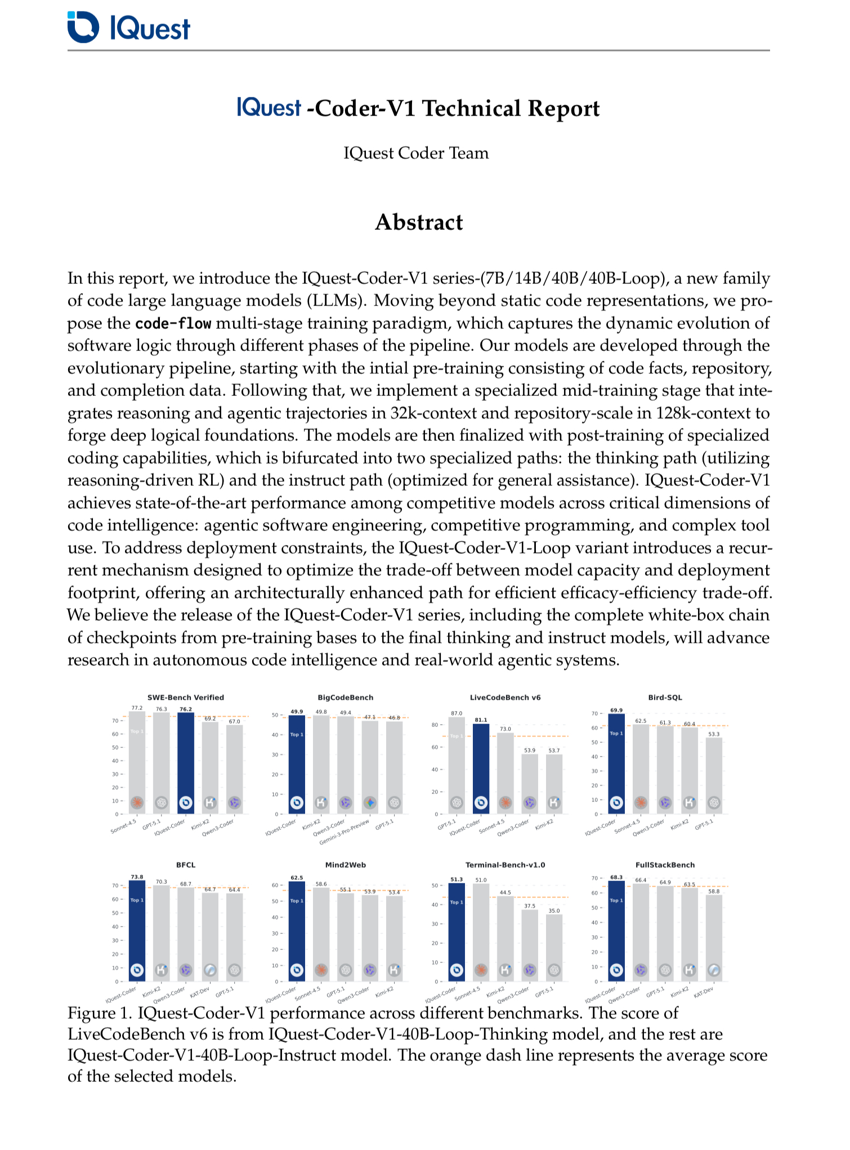
IQuest-Coder-V1 Technical Report
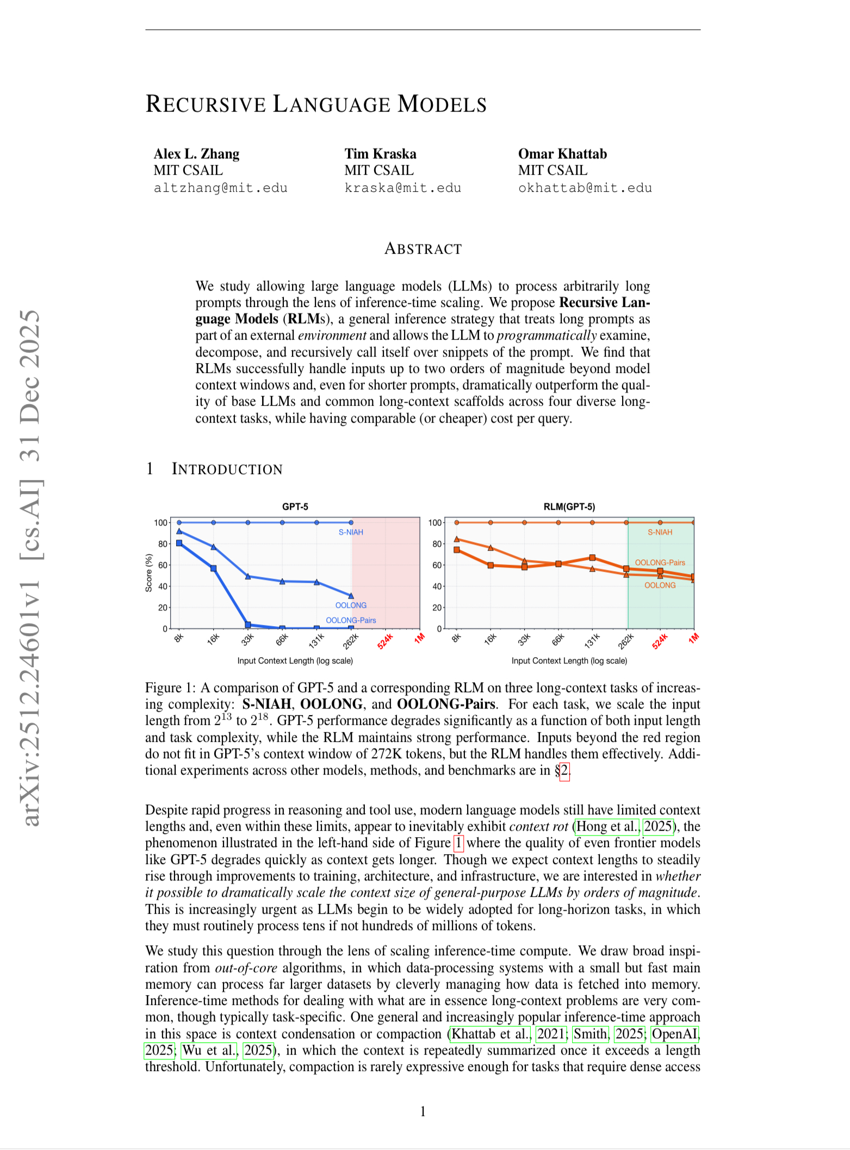
Recursive Language Models
FlowBlending: Stage-Aware Multi-Model Sampling for Fast and High-Fidelity Video Generation
Benchmark^2: Systematic Evaluation of LLM Benchmarks
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Entropy-Adaptive Fine-Tuning: Resolving Confident Conflicts to Mitigate Forgetting
Diversity or Precision? A Deep Dive into Next Token Prediction
Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
DreamStyle: A Unified Framework for Video Stylization
UniCorn: Towards Self-Improving Unified Multimodal Models through Self-Generated Supervision
LTX-2: Efficient Joint Audio-Visual Foundation Model
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
MOSS Transcribe Diarize: Accurate Transcription with Speaker Diarization
InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
Adaptation of Agentic AI
Large Video Planner Enables Generalizable Robot Control
InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
GARDO: Reinforcing Diffusion Models without Reward Hacking
VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer
NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
K-EXAONE Technical Report
The Hunger Game Debate: On the Emergence of Over-Competition in Multi-Agent Systems
Training AI Co-Scientists Using Rubric Rewards
AdaGaR: Adaptive Gabor Representation for Dynamic Scene Reconstruction
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
IQuest-Coder-V1 Technical Report
Recursive Language Models
FlowBlending: Stage-Aware Multi-Model Sampling for Fast and High-Fidelity Video Generation