HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
DTS:通过解码树草图增强大型推理模型
推理
LLM
Zicheng Xu, Guanchu Wang, Yu-Neng Chuang, et al.
基于LLMs的贝叶斯优化自适应核设计宛如轻而易举之事
LLM
建模
Richard Cornelius Suwandi, Feng Yin, Juntao Wang, et al.
DePass:通过简单分解前向传播实现统一特征归因
Transformer
自然语言处理
Xiangyu Hong, Che Jiang, Kai Tian, et al.
COOPER:面向空间智能的协同感知与推理统一模型
多模态
多任务学习
Zefeng Zhang, Xiangzhao Hao, Hengzhu Tang, et al.
从模仿到判别:迈向一种增强跨领域推理任务的通用课程优势机制
强化学习
LLM
Changpeng Yang, Jinyang Wu, Yuchen Liu, et al.
PaCo-RL:基于成对奖励建模的强化学习在一致图像生成中的应用进展
强化学习
文生图
Bowen Ping, Chengyou Jia, Minnan Luo, et al.
EMMA:基于统一架构的高效多模态理解、生成与编辑
统一多模态
多任务学习
Xin He, Longhui Wei, Jianbo Ouyang, et al.
EditThinker:解锁任意图像编辑器的迭代推理能力
推理
图像生成
Hongyu Li, Manyuan Zhang, Dian Zheng, et al.
TwinFlow:基于自对抗流实现大模型的一步生成
扩散模型
文生图
Zhenglin Cheng, Peng Sun, Jianguo Li, et al.
CARE-PD:用于帕金森病步态评估的多中心匿名临床数据集
视频理解
数据集
Vida Adeli, Ivan Klabucar, Javad Rajabi, et al.
WenetSpeech-Chuan:一个用于方言语音处理的大规模四川话语料库,具有丰富的标注信息
音频和语音处理
数据集
Yuhang Dai, Ziyu Zhang, Shuai Wang, et al.
PolypSense3D:用于内窥镜深度感知息肉尺寸测量的多源基准数据集
深度估计
语义分割
Ruyu Liu, Lin Wang, Zhou Mingming, et al.
PhysDrive:面向车载驾驶员监控的多模态远程生理测量数据集
多模态
计算机视觉
Jiyao Wang, Xiao Yang, Qingyong Hu, et al.
人工蜂群智能:语言模型(及更广泛领域)的开放性同质性
LLM
数据集
Liwei Jiang, Yuanjun Chai, Margaret Li, et al.
OmniSVG:一种统一的可扩展矢量图形生成模型
图像生成
文生图
Yiying Yang, Wei Cheng, Sijin Chen, et al.
算法思维理论
推理
LLM
MohammadHossein Bateni, Vincent Cohen-Addad, Yuzhou Gu, et al.
机器人世界模型:用于机器人鲁棒策略优化的神经网络模拟器
机器人技术
强化学习
Chenhao Li, Andreas Krause, Marco Hutter
奖励强制:基于奖励分布匹配蒸馏的高效流式视频生成
视频生成
扩散模型
Yunhong Lu, Yanhong Zeng, Haobo Li, et al.
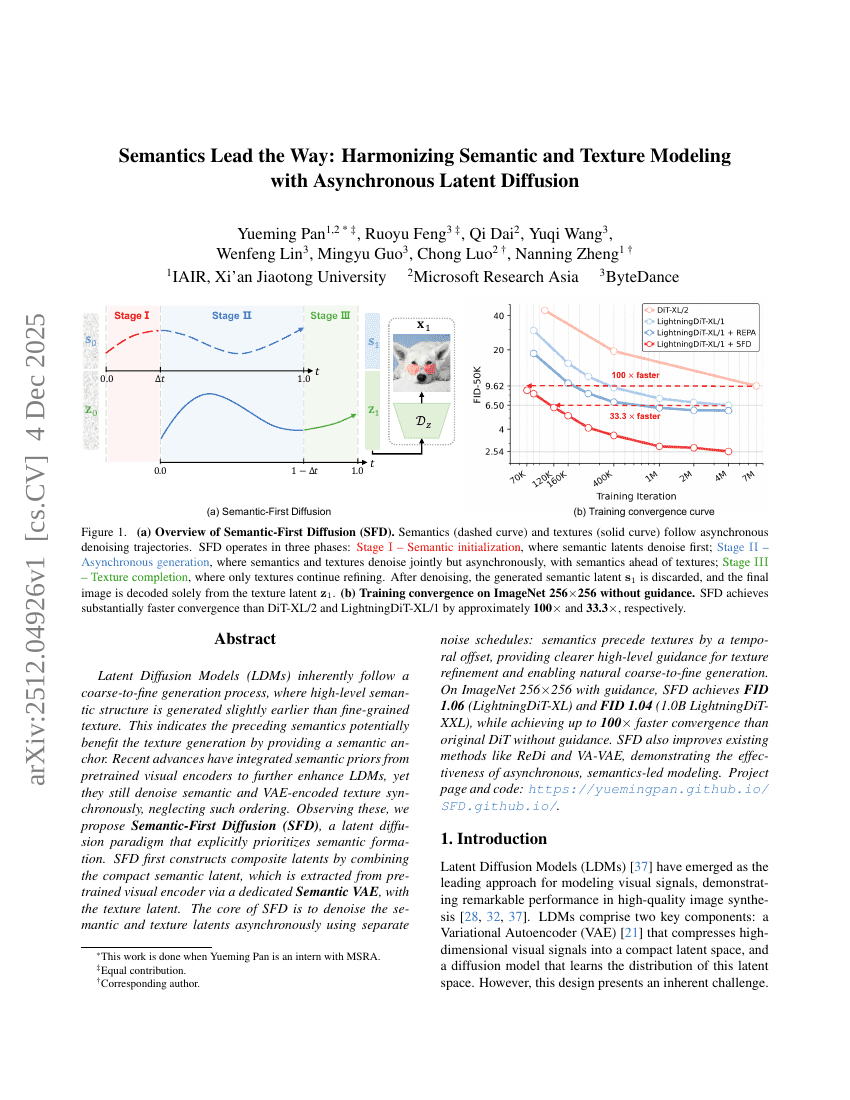
语义引领方向:通过异步潜在扩散实现语义与纹理建模的协同
扩散模型
图像生成
Yueming Pan, Ruoyu Feng, Qi Dai, et al.
ARM-Thinker:通过智能体工具使用与视觉推理强化多模态生成式奖励模型
Agent
偏好
Shengyuan Ding, Xinyu Fang, Ziyu Liu, et al.
Nex-N1:通过统一生态系统训练的智能体模型,用于大规模环境构建
Agent
LLM
Nex-AGI Team, Yuxuan Cai, Lu Chen, et al.
DAComp:面向数据智能全生命周期的数据Agent基准测试
基准
Agent
Fangyu Lei, Jinxiang Meng, Yiming Huang, et al.
实时虚拟形象:基于实时音频驱动的无限长度虚拟形象生成
扩散模型
合成
Yubo Huang, Hailong Guo, Fangtai Wu, et al.
F5-TTS:一种通过流匹配实现流畅且忠实语音伪造的童话讲述者
语音生成
Transformer
Yushen Chen, Zhikang Niu, Ziyang Ma, et al.
VOccl3D:一种用于真实遮挡下3D人体姿态与形状估计的视频基准数据集
视频理解
目标检测
Yash Garg, Saketh Bachu, Arindam Dutta, et al.
Alpamayo-R1:面向长尾场景下可泛化的自动驾驶,连接推理与行为预测
推理
强化学习
NVIDIA, Yulong Cao, Tong Che, et al.
环环相扣:一场关于测试时记忆、注意力偏差、保留与在线优化的探索之旅
神经网络
Transformer
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, et al.
重新思考文本到视觉生成中推理时扩展的提示设计
文生图
扩散模型
Subin Kim, Sangwoo Mo, Mamshad Nayeem Rizve, et al.
作为反探索的视觉-语言-动作模型引导:一种测试时扩展方法
统一多模态
监督式微调
Siyuan Yang, Yang Zhang, Haoran He, et al.
OneThinker:面向图像与视频的全功能推理模型
视觉问答
多任务学习
Kaituo Feng, Manyuan Zhang, Hongyu Li, et al.
ViDiC:视频差异描述
视频描述
多模态
Jiangtao Wu, Shihao Li, Zhaozhou Bian, et al.
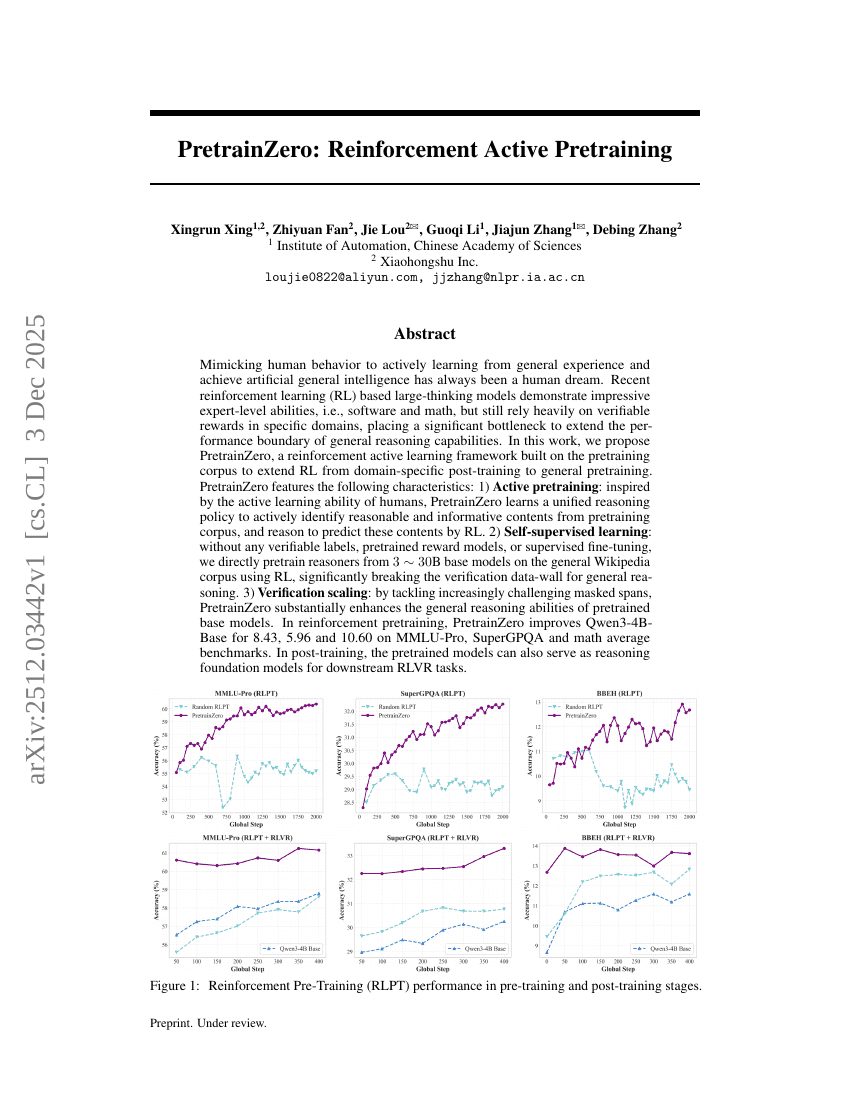
PretrainZero:强化主动预训练
强化学习
推理
Xingrun Xing, Zhiyuan Fan, Jie Lou, et al.
1
9
10
11
12
13
14
15
48
DTS:通过解码树草图增强大型推理模型
推理
LLM
Zicheng Xu, Guanchu Wang, Yu-Neng Chuang, et al.
基于LLMs的贝叶斯优化自适应核设计宛如轻而易举之事
LLM
建模
Richard Cornelius Suwandi, Feng Yin, Juntao Wang, et al.
DePass:通过简单分解前向传播实现统一特征归因
Transformer
自然语言处理
Xiangyu Hong, Che Jiang, Kai Tian, et al.
COOPER:面向空间智能的协同感知与推理统一模型
多模态
多任务学习
Zefeng Zhang, Xiangzhao Hao, Hengzhu Tang, et al.
从模仿到判别:迈向一种增强跨领域推理任务的通用课程优势机制
强化学习
LLM
Changpeng Yang, Jinyang Wu, Yuchen Liu, et al.
PaCo-RL:基于成对奖励建模的强化学习在一致图像生成中的应用进展
强化学习
文生图
Bowen Ping, Chengyou Jia, Minnan Luo, et al.
EMMA:基于统一架构的高效多模态理解、生成与编辑
统一多模态
多任务学习
Xin He, Longhui Wei, Jianbo Ouyang, et al.
EditThinker:解锁任意图像编辑器的迭代推理能力
推理
图像生成
Hongyu Li, Manyuan Zhang, Dian Zheng, et al.
TwinFlow:基于自对抗流实现大模型的一步生成
扩散模型
文生图
Zhenglin Cheng, Peng Sun, Jianguo Li, et al.
CARE-PD:用于帕金森病步态评估的多中心匿名临床数据集
视频理解
数据集
Vida Adeli, Ivan Klabucar, Javad Rajabi, et al.
WenetSpeech-Chuan:一个用于方言语音处理的大规模四川话语料库,具有丰富的标注信息
音频和语音处理
数据集
Yuhang Dai, Ziyu Zhang, Shuai Wang, et al.
PolypSense3D:用于内窥镜深度感知息肉尺寸测量的多源基准数据集
深度估计
语义分割
Ruyu Liu, Lin Wang, Zhou Mingming, et al.
PhysDrive:面向车载驾驶员监控的多模态远程生理测量数据集
多模态
计算机视觉
Jiyao Wang, Xiao Yang, Qingyong Hu, et al.
人工蜂群智能:语言模型(及更广泛领域)的开放性同质性
LLM
数据集
Liwei Jiang, Yuanjun Chai, Margaret Li, et al.
OmniSVG:一种统一的可扩展矢量图形生成模型
图像生成
文生图
Yiying Yang, Wei Cheng, Sijin Chen, et al.
算法思维理论
推理
LLM
MohammadHossein Bateni, Vincent Cohen-Addad, Yuzhou Gu, et al.
机器人世界模型:用于机器人鲁棒策略优化的神经网络模拟器
机器人技术
强化学习
Chenhao Li, Andreas Krause, Marco Hutter
奖励强制:基于奖励分布匹配蒸馏的高效流式视频生成
视频生成
扩散模型
Yunhong Lu, Yanhong Zeng, Haobo Li, et al.
语义引领方向:通过异步潜在扩散实现语义与纹理建模的协同
扩散模型
图像生成
Yueming Pan, Ruoyu Feng, Qi Dai, et al.
ARM-Thinker:通过智能体工具使用与视觉推理强化多模态生成式奖励模型
Agent
偏好
Shengyuan Ding, Xinyu Fang, Ziyu Liu, et al.
Nex-N1:通过统一生态系统训练的智能体模型,用于大规模环境构建
Agent
LLM
Nex-AGI Team, Yuxuan Cai, Lu Chen, et al.
DAComp:面向数据智能全生命周期的数据Agent基准测试
基准
Agent
Fangyu Lei, Jinxiang Meng, Yiming Huang, et al.
实时虚拟形象:基于实时音频驱动的无限长度虚拟形象生成
扩散模型
合成
Yubo Huang, Hailong Guo, Fangtai Wu, et al.
F5-TTS:一种通过流匹配实现流畅且忠实语音伪造的童话讲述者
语音生成
Transformer
Yushen Chen, Zhikang Niu, Ziyang Ma, et al.
VOccl3D:一种用于真实遮挡下3D人体姿态与形状估计的视频基准数据集
视频理解
目标检测
Yash Garg, Saketh Bachu, Arindam Dutta, et al.
Alpamayo-R1:面向长尾场景下可泛化的自动驾驶,连接推理与行为预测
推理
强化学习
NVIDIA, Yulong Cao, Tong Che, et al.
环环相扣:一场关于测试时记忆、注意力偏差、保留与在线优化的探索之旅
神经网络
Transformer
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, et al.
重新思考文本到视觉生成中推理时扩展的提示设计
文生图
扩散模型
Subin Kim, Sangwoo Mo, Mamshad Nayeem Rizve, et al.
作为反探索的视觉-语言-动作模型引导:一种测试时扩展方法
统一多模态
监督式微调
Siyuan Yang, Yang Zhang, Haoran He, et al.
OneThinker:面向图像与视频的全功能推理模型
视觉问答
多任务学习
Kaituo Feng, Manyuan Zhang, Hongyu Li, et al.
ViDiC:视频差异描述
视频描述
多模态
Jiangtao Wu, Shihao Li, Zhaozhou Bian, et al.
PretrainZero:强化主动预训练
强化学习
推理
Xingrun Xing, Zhiyuan Fan, Jie Lou, et al.
1
9
10
11
12
13
14
15
48