HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
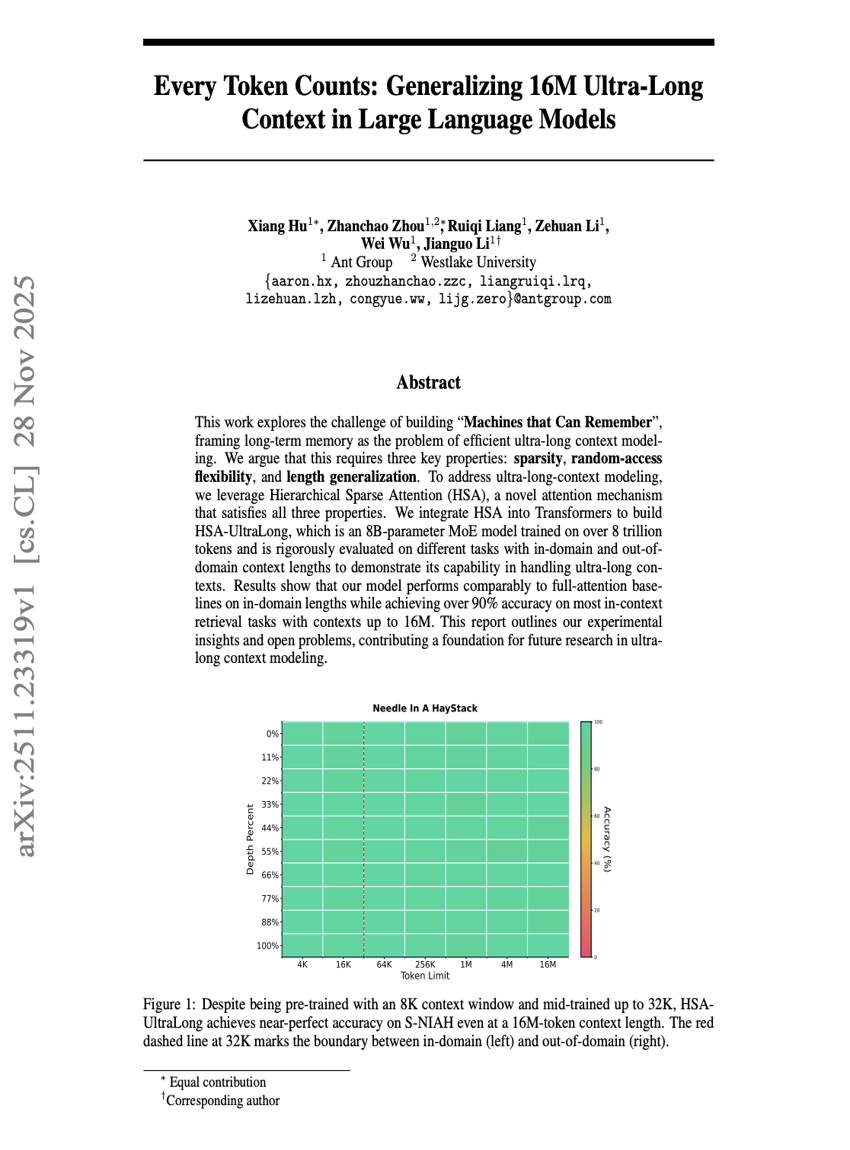
每个Token都至关重要:在大型语言模型中泛化16M超长上下文
LLM
Transformer
Xiang Hu, Zhanchao Zhou, Ruiqi Liang, et al.
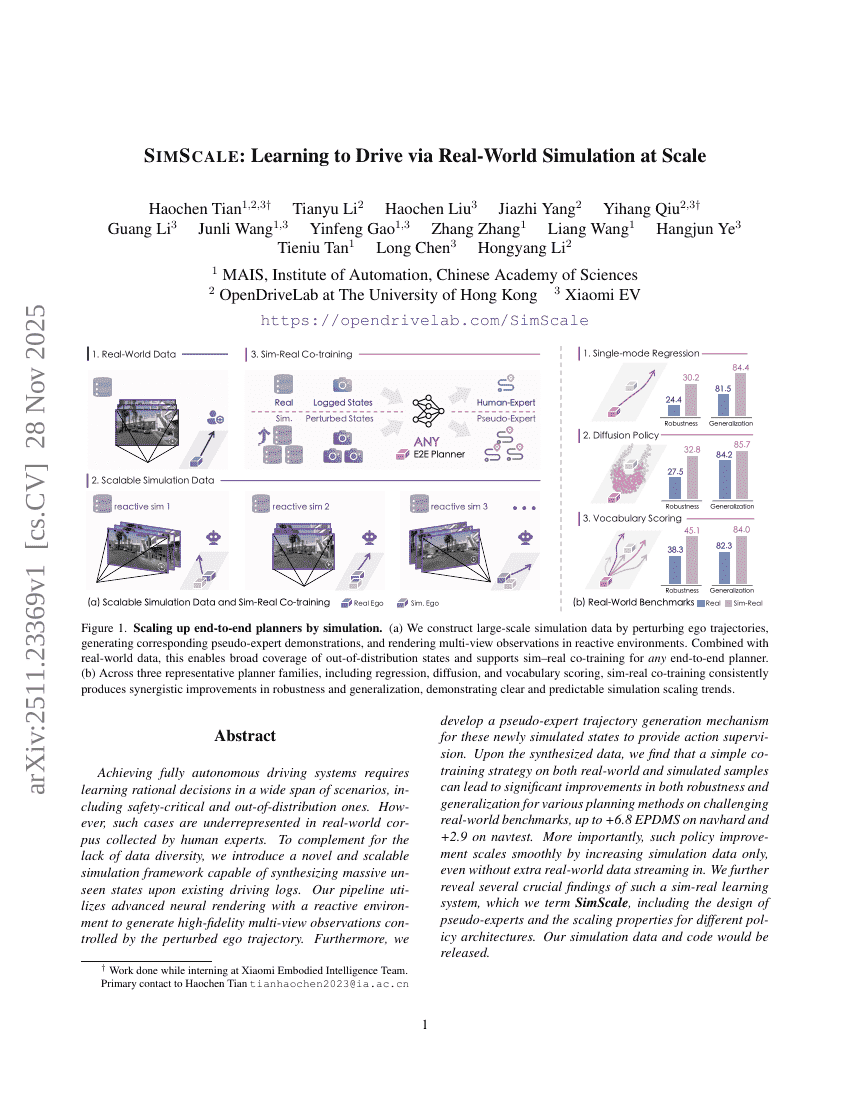
SimScale:通过大规模真实世界仿真学习驾驶
自动驾驶
合成
Haochen Tian, Tianyu Li, Haochen Liu, et al.
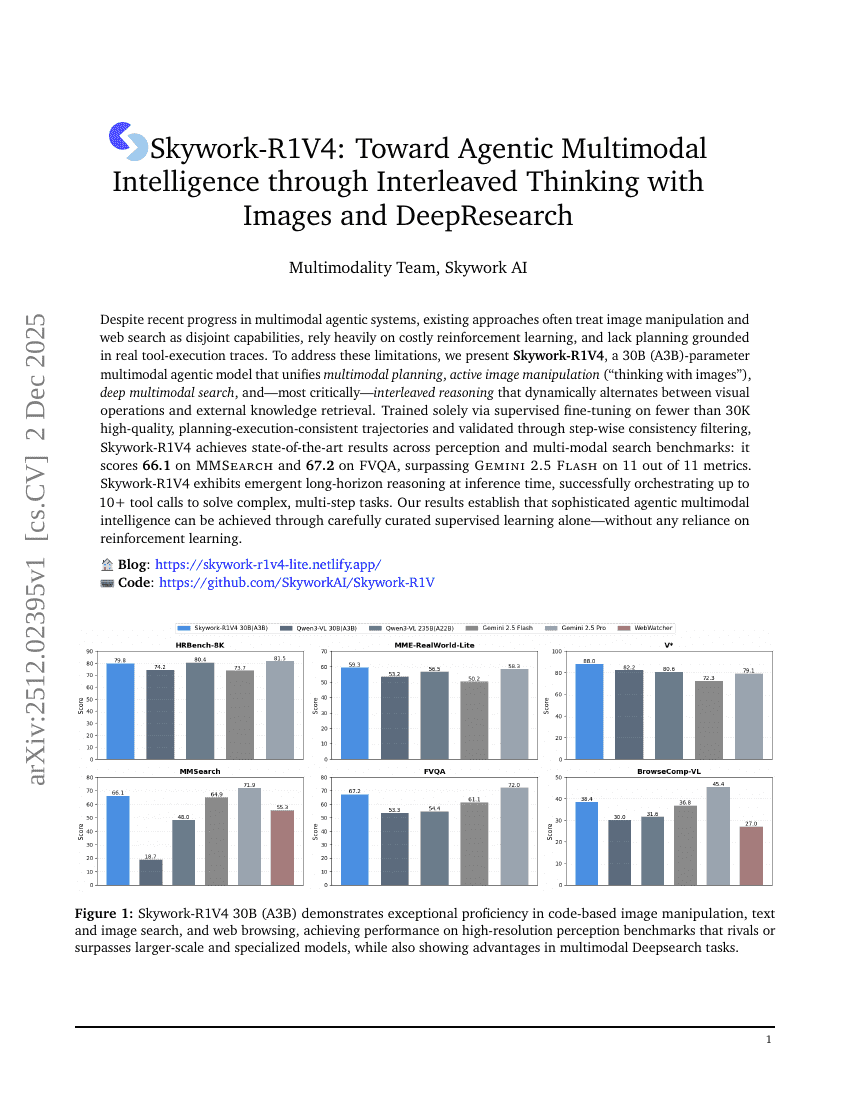
Skywork-R1V4:通过图像与DeepResearch的交织思维迈向智能多模态代理
Agent
检索增强生成
Yifan Zhang, Liang Hu, Haofeng Sun, et al.
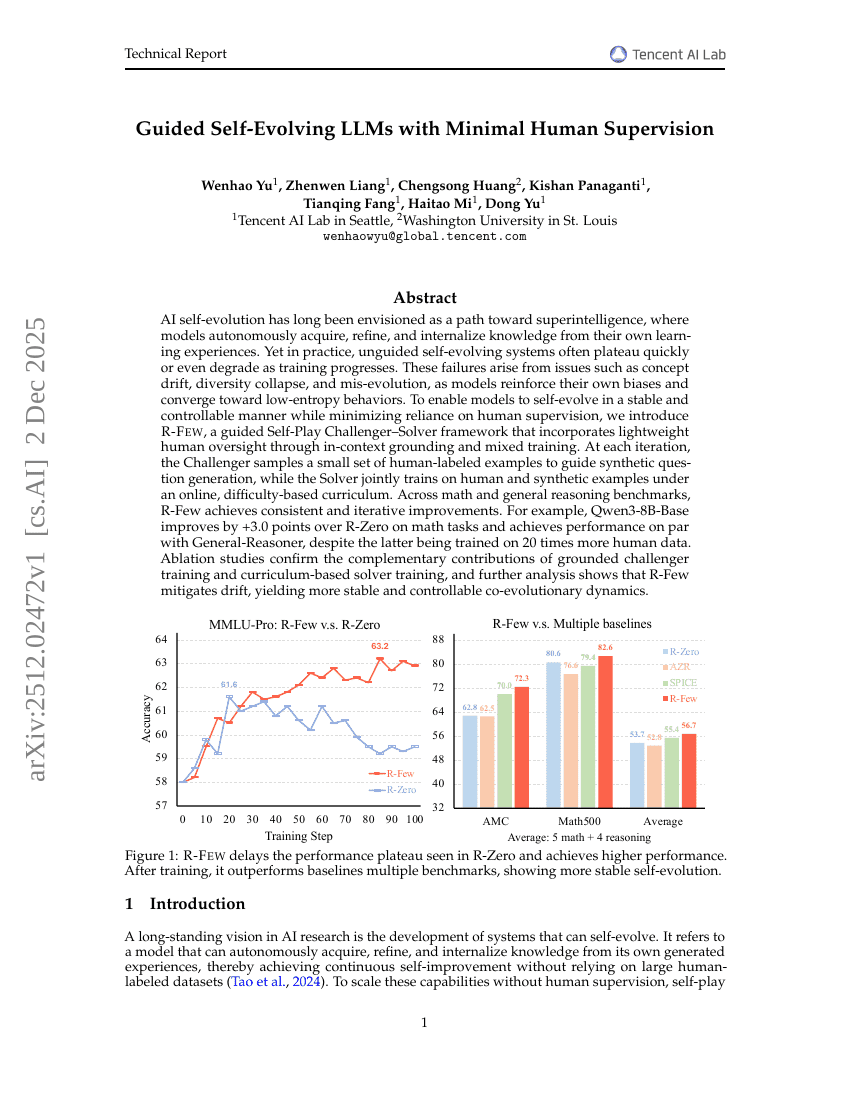
基于最小人类监督的引导式自进化LLM
LLM
推理
Wenhao Yu, Zhenwen Liang, Chengsong Huang, et al.
MultiShotMaster:一种可控制的多镜头视频生成框架
视频生成
文生视频
Qinghe Wang, Xiaoyu Shi, Baolu Li, et al.
MG-Nav:通过稀疏空间记忆实现的双尺度视觉导航
计算机视觉
目标检测
Bo Wang, Jiehong Lin, Chenzhi Liu, et al.
一致性评论者:通过参考引导的注意力对齐修正生成图像中的不一致性
图生图
图像生成
Ziheng Ouyang, Yiren Song, Yaoli Liu, et al.
我们距离真正有用的深度研究Agent还有多远?
基准
数据集
Dingling Zhang, He Zhu, Jincheng Ren, et al.
基于LLM的强化学习稳定性优化:方法与实践
强化学习
LLM
Chujie Zheng, Kai Dang, Bowen Yu, et al.
Envision:面向因果世界过程洞察的统一理解与生成基准测试
文生图
统一多模态
Juanxi Tian, Siyuan Li, Conghui He, et al.
LongVT:通过原生工具调用激励“以长视频进行思考”
视频理解
视觉问答
Zuhao Yang, Sudong Wang, Kaichen Zhang, et al.
从代码基础模型到Agent与应用:代码智能实用指南
LLM
监督式微调
Jian Yang, Wei Zhang, Shark Liu, et al.
基于物理驱动的时空建模用于AI生成视频检测
视频理解
视频生成
Shuhai Zhang, ZiHao Lian, Jiahao Yang, et al.
Mem-α:通过强化学习学习记忆构建
强化学习
Agent
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, et al.
搜索自对弈:在无监督条件下推进Agent能力的边界
强化学习
Agent
Hongliang Lu, Yuhang Wen, Pengyu Cheng, et al.
CudaForge:一种支持硬件反馈的CUDA内核优化Agent框架
LLM
代码生成
Zijian Zhang, Rong Wang, Shiyang Li, et al.
ScaleNet:通过增量参数扩展预训练神经网络
Transformer
神经网络
Zhiwei Hao, Jianyuan Guo, Li Shen, et al.
优化块注意力混合
LLM
Transformer
Guangxuan Xiao, Junxian Guo, Kasra Mazaheri, et al.
分形取证:通过分形水印实现主动式深度伪造检测与定位
计算机视觉
深度学习
Tianyi Wang, Harry Cheng, Ming-Hui Liu, et al.
思维链劫持
LLM
推理
Jianli Zhao, Tingchen Fu, Rylan Schaeffer, et al.
InstanceAssemble:通过实例组装注意力实现布局感知的图像生成
扩散模型
文生图
Qiang Xiang, Shuang Sun, Binglei Li, et al.
3EED:在三维空间中处处实现万物具身化
机器视觉 3D
多模态
Rong Li, Yuhao Dong, Tianshuai Hu, et al.
DetectiumFire:一个全面的多模态数据集,连接视觉与语言以实现火灾理解
多模态
视频理解
Zixuan Liu, Siavash H. Khajavi, Guangkai Jiang
CHIP:工业场景中椅子6D位姿估计的多传感器数据集
机器视觉 3D
机器人技术
Mattia Nardon, Mikel Mujika Agirre, Ander González Tomé, et al.
几何约束Agent用于空间推理
Agent
推理
Zeren Chen, Xiaoya Lu, Zhijie Zheng, et al.
DeepSeek-V3.2:推动开源大型语言模型的前沿
DeepSeek
推理
DeepSeek-AI, Aixin Liu, Aoxue Mei, et al.
DiP:在像素空间中驯服扩散模型
扩散模型
图像生成
Zhennan Chen, Junwei Zhu, Xu Chen, et al.
架构解耦并非构建统一多模态模型的全部所需
统一多模态
多任务学习
Dian Zheng, Manyuan Zhang, Hongyu Li, et al.
大规模视觉桥接Transformer
Transformer
图生视频
Zhenxiong Tan, Zeqing Wang, Xingyi Yang, et al.
AnyTalker:通过交互式优化实现多人物对话视频生成的扩展
视频生成
多模态
Zhizhou Zhong, Yicheng Ji, Zhe Kong, et al.
REASONEDIT:面向推理增强的图像编辑模型
文生图
扩散模型
Fukun Yin, Shiyu Liu, Yucheng Han, et al.
OpenApps:通过模拟环境变化来衡量UI-Agent的可靠性
Agent
基准
Karen Ullrich, Jingtong Su, Claudia Shi, et al.
1
10
11
12
13
14
15
16
48
每个Token都至关重要:在大型语言模型中泛化16M超长上下文
LLM
Transformer
Xiang Hu, Zhanchao Zhou, Ruiqi Liang, et al.
SimScale:通过大规模真实世界仿真学习驾驶
自动驾驶
合成
Haochen Tian, Tianyu Li, Haochen Liu, et al.
Skywork-R1V4:通过图像与DeepResearch的交织思维迈向智能多模态代理
Agent
检索增强生成
Yifan Zhang, Liang Hu, Haofeng Sun, et al.
基于最小人类监督的引导式自进化LLM
LLM
推理
Wenhao Yu, Zhenwen Liang, Chengsong Huang, et al.
MultiShotMaster:一种可控制的多镜头视频生成框架
视频生成
文生视频
Qinghe Wang, Xiaoyu Shi, Baolu Li, et al.
MG-Nav:通过稀疏空间记忆实现的双尺度视觉导航
计算机视觉
目标检测
Bo Wang, Jiehong Lin, Chenzhi Liu, et al.
一致性评论者:通过参考引导的注意力对齐修正生成图像中的不一致性
图生图
图像生成
Ziheng Ouyang, Yiren Song, Yaoli Liu, et al.
我们距离真正有用的深度研究Agent还有多远?
基准
数据集
Dingling Zhang, He Zhu, Jincheng Ren, et al.
基于LLM的强化学习稳定性优化:方法与实践
强化学习
LLM
Chujie Zheng, Kai Dang, Bowen Yu, et al.
Envision:面向因果世界过程洞察的统一理解与生成基准测试
文生图
统一多模态
Juanxi Tian, Siyuan Li, Conghui He, et al.
LongVT:通过原生工具调用激励“以长视频进行思考”
视频理解
视觉问答
Zuhao Yang, Sudong Wang, Kaichen Zhang, et al.
从代码基础模型到Agent与应用:代码智能实用指南
LLM
监督式微调
Jian Yang, Wei Zhang, Shark Liu, et al.
基于物理驱动的时空建模用于AI生成视频检测
视频理解
视频生成
Shuhai Zhang, ZiHao Lian, Jiahao Yang, et al.
Mem-α:通过强化学习学习记忆构建
强化学习
Agent
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, et al.
搜索自对弈:在无监督条件下推进Agent能力的边界
强化学习
Agent
Hongliang Lu, Yuhang Wen, Pengyu Cheng, et al.
CudaForge:一种支持硬件反馈的CUDA内核优化Agent框架
LLM
代码生成
Zijian Zhang, Rong Wang, Shiyang Li, et al.
ScaleNet:通过增量参数扩展预训练神经网络
Transformer
神经网络
Zhiwei Hao, Jianyuan Guo, Li Shen, et al.
优化块注意力混合
LLM
Transformer
Guangxuan Xiao, Junxian Guo, Kasra Mazaheri, et al.
分形取证:通过分形水印实现主动式深度伪造检测与定位
计算机视觉
深度学习
Tianyi Wang, Harry Cheng, Ming-Hui Liu, et al.
思维链劫持
LLM
推理
Jianli Zhao, Tingchen Fu, Rylan Schaeffer, et al.
InstanceAssemble:通过实例组装注意力实现布局感知的图像生成
扩散模型
文生图
Qiang Xiang, Shuang Sun, Binglei Li, et al.
3EED:在三维空间中处处实现万物具身化
机器视觉 3D
多模态
Rong Li, Yuhao Dong, Tianshuai Hu, et al.
DetectiumFire:一个全面的多模态数据集,连接视觉与语言以实现火灾理解
多模态
视频理解
Zixuan Liu, Siavash H. Khajavi, Guangkai Jiang
CHIP:工业场景中椅子6D位姿估计的多传感器数据集
机器视觉 3D
机器人技术
Mattia Nardon, Mikel Mujika Agirre, Ander González Tomé, et al.
几何约束Agent用于空间推理
Agent
推理
Zeren Chen, Xiaoya Lu, Zhijie Zheng, et al.
DeepSeek-V3.2:推动开源大型语言模型的前沿
DeepSeek
推理
DeepSeek-AI, Aixin Liu, Aoxue Mei, et al.
DiP:在像素空间中驯服扩散模型
扩散模型
图像生成
Zhennan Chen, Junwei Zhu, Xu Chen, et al.
架构解耦并非构建统一多模态模型的全部所需
统一多模态
多任务学习
Dian Zheng, Manyuan Zhang, Hongyu Li, et al.
大规模视觉桥接Transformer
Transformer
图生视频
Zhenxiong Tan, Zeqing Wang, Xingyi Yang, et al.
AnyTalker:通过交互式优化实现多人物对话视频生成的扩展
视频生成
多模态
Zhizhou Zhong, Yicheng Ji, Zhe Kong, et al.
REASONEDIT:面向推理增强的图像编辑模型
文生图
扩散模型
Fukun Yin, Shiyu Liu, Yucheng Han, et al.
OpenApps:通过模拟环境变化来衡量UI-Agent的可靠性
Agent
基准
Karen Ullrich, Jingtong Su, Claudia Shi, et al.
1
10
11
12
13
14
15
16
48