HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
倾听内心的声音:通过中间特征反馈对齐ControlNet训练
扩散模型
图像生成
Nina Konovalova, Maxim Nikolaev, Andrey Kuznetsov, et al.
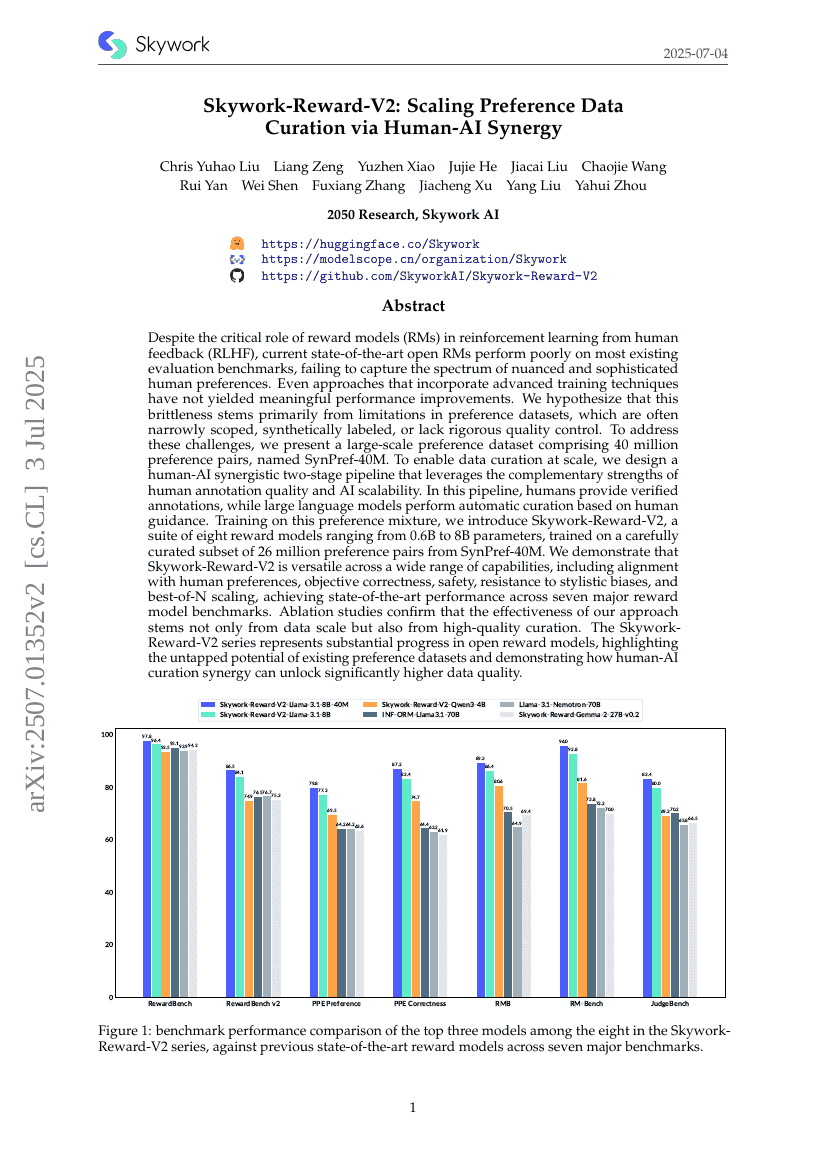
Skywork-Reward-V2:通过人机协同扩展偏好数据管理
偏好
数据集
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, et al.
LangScene-X:利用TriMap视频扩散重建可泛化的3D语言嵌入场景
统一多模态
3D 生成
Fangfu Liu, Hao Li, Jiawei Chi, et al.
基于图像的多模态推理:基础、方法与未来前沿
多模态
推理
Zhaochen Su, Peng Xia, Hangyu Guo, et al.
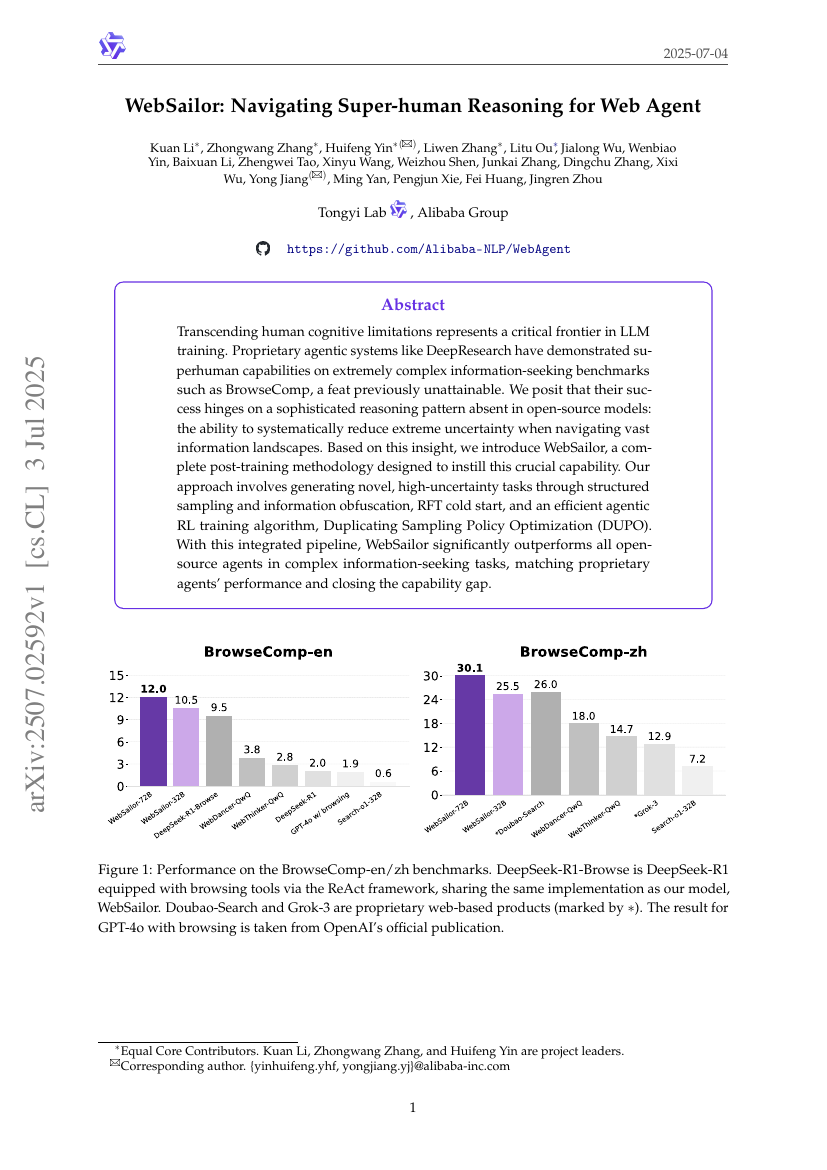
WebSailor:用于网络代理的超人类推理导航
Agent
推理
Kuan Li, Zhongwang Zhang, Huifeng Yin, et al.
EmoBench-M:面向多模态大语言模型的情感智能基准测试
情绪识别
多模态
He Hu, Yucheng Zhou, Lianzhong You, et al.
机器学习中的AI研究代理:在MLE-bench中进行搜索、探索与泛化
强化学习
AI for Science
Edan Toledo, Karen Hambardzumyan, Martin Josifoski, et al.
局部感知的并行解码用于高效的自回归图像生成
图像生成
Transformer
Zhuoyang Zhang, Luke J. Huang, Chengyue Wu, et al.
FreeMorph:无需调参的扩散模型通用图像变形
扩散模型
图生图
Yukang Cao, Chenyang Si, Jinghao Wang, et al.
视觉-语言-动作模型综述:从动作分词的角度出发
多模态
自然语言处理
Yifan Zhong, Fengshuo Bai, Shaofei Cai, et al.
在任意条件下测量任何深度
深度估计
机器视觉 3D
Boyuan Sun, Modi Jin, Bowen Yin, et al.
LongAnimation:基于动态全局-局部记忆的长动画生成
视频生成
视频理解
Nan Chen, Mengqi Huang, Yihao Meng, et al.
快手 Keye-VL 技术报告
视频理解
多模态
Kwai Keye Team, Biao Yang, Bin Wen, et al.
自动驾驶中视觉-语言-行为模型的综述
多模态
自动驾驶
Sicong Jiang, Zilin Huang, Kangan Qian, et al.
MoCa:模态感知的持续预训练生成更优的双向多模态嵌入
多模态表征
Transformer
Haonan Chen, Hong Liu, Yuping Luo, et al.
FreeLong++:通过多频带谱融合实现无训练长视频生成
视频生成
文生视频
Yu Lu, Yi Yang
超越符号:从脑启发智能到人工通用智能的认知基础及其社会影响
Agent
推理
Rizwan Qureshi, Ranjan Sapkota, Abbas Shah, et al.
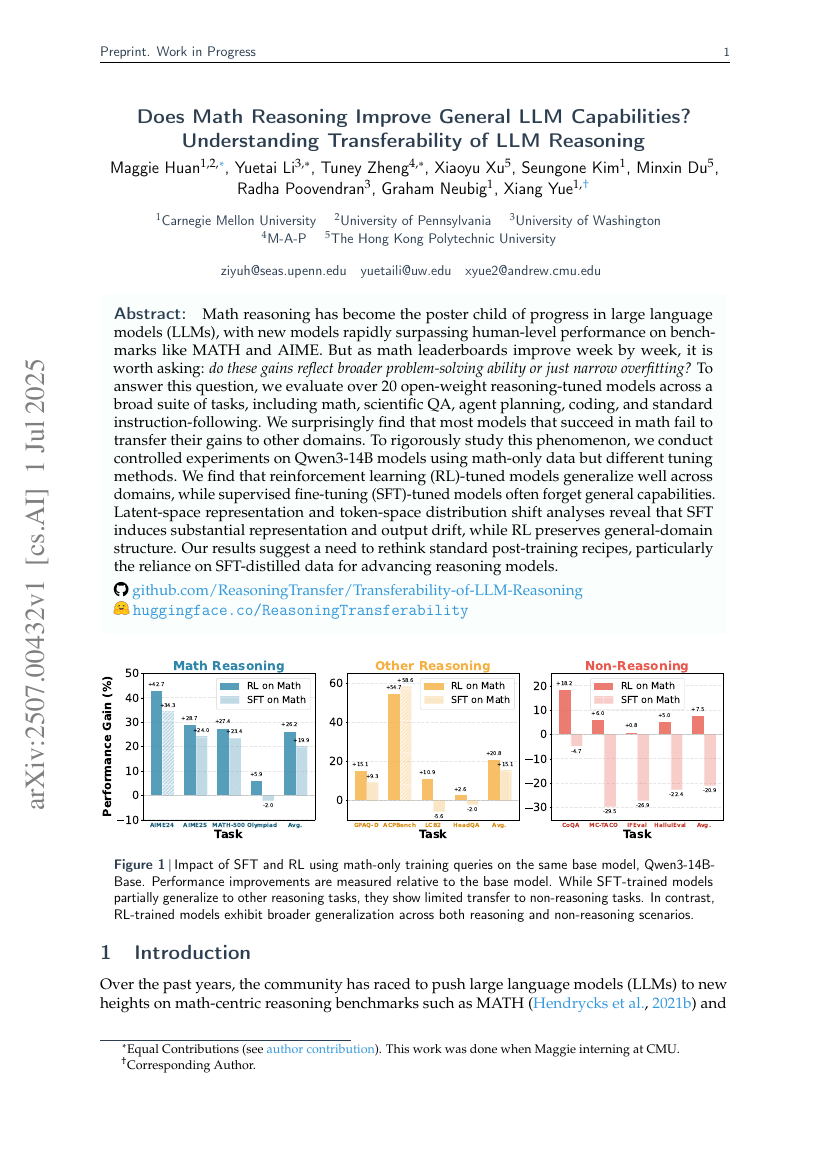
数学推理是否提升通用大语言模型的能力?理解大语言模型推理的可迁移性
监督式微调
模型训练
Maggie Huan, Yuetai Li, Tuney Zheng, et al.
SciArena:科学文献任务中基础模型的开放评估平台
LLM
偏好
Yilun Zhao, Kaiyan Zhang, Tiansheng Hu, et al.
医学中的整体人工智能:性能提升与可解释性增强
多模态
多模态表征
Periklis Petridis, Georgios Margaritis, Vasiliki Stoumpou, et al.
evolving prompts in-context: 一种开放式的、自我复制的视角
LLM
推理
Wang, Jianyu, Hu, et al.
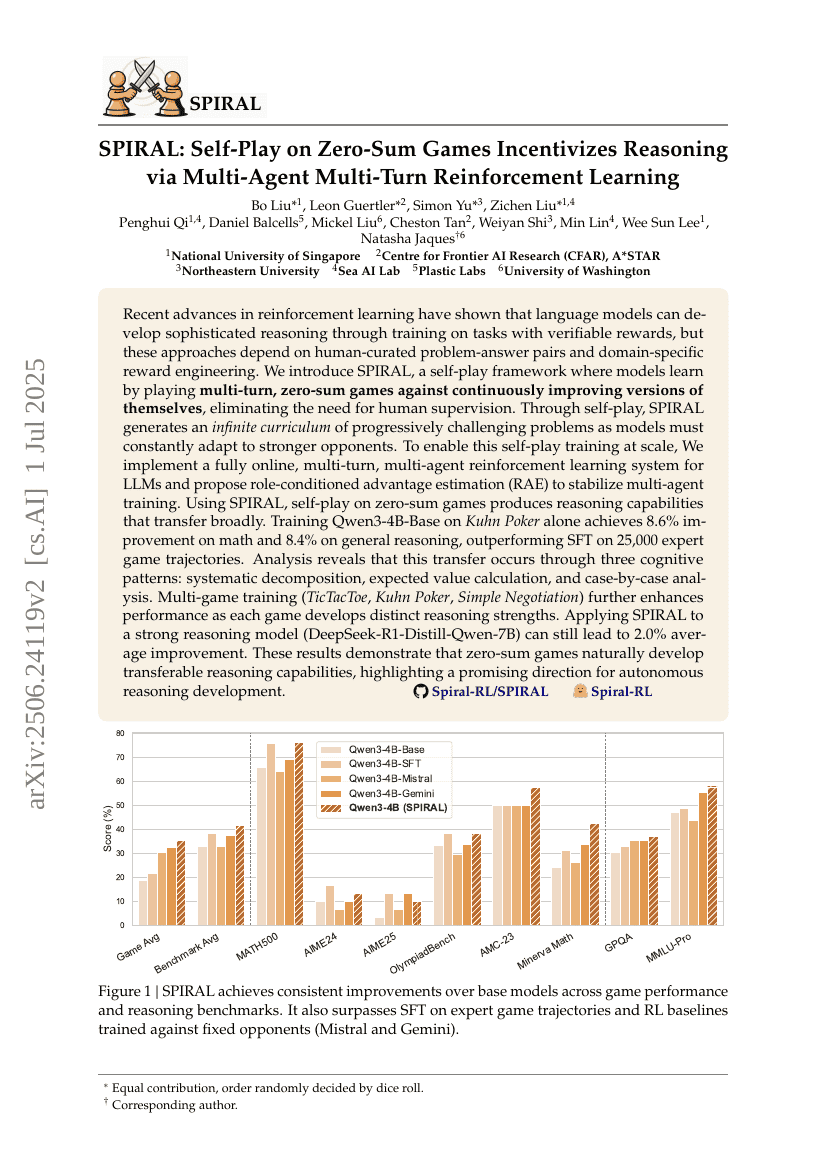
SPIRAL:零和博弈中的自我对弈通过多智能体多轮强化学习激励推理
强化学习
推理
Bo Liu, Leon Guertler, Simon Yu, et al.
面向听者的奖励性思考在视觉语言模型中的图像偏好研究
偏好
推理
Alexander Gambashidze, Li Pengyi, Matvey Skripkin, et al.
Calligrapher:自由风格文本图像定制
扩散模型
文生图
Yue Ma, Qingyan Bai, Hao Ouyang, et al.
VMoBA:视频扩散模型中的块注意力混合方法
Transformer
视频生成
Jianzong Wu, Liang Hou, Haotian Yang, et al.
SMMILE:一种专家驱动的多模态医学情境学习基准
多模态
基准
Melanie Rieff, Maya Varma, Ossian Rabow, et al.
自动LLM速通基准:重现NanoGPT改进
基准
LLM
Bingchen Zhao, Despoina Magka, Minqi Jiang, et al.
Shape-for-Motion:基于3D代理的精确一致视频编辑
3D 模型
视频处理
Yuhao Liu, Tengfei Wang, Fang Liu, et al.
从理想到现实:面向实际场景的统一且数据高效的密集预测
语义分割
多任务学习
Changliang Xia, Chengyou Jia, Zhuohang Dang, et al.
ShotBench:视觉-语言模型中的专家级电影理解
视觉问答
多模态
Hongbo Liu, Jingwen He, Yi Jin, et al.
XVerse:通过DiT调制实现一致的多主体身份和语义属性控制
文生图
扩散模型
Bowen Chen, Mengyi Zhao, Haomiao Sun, et al.
24孔板中的零样本抗体设计
AI for Science
多模态
Chai Discovery Team
1
41
42
43
44
45
46
47
48
倾听内心的声音:通过中间特征反馈对齐ControlNet训练
扩散模型
图像生成
Nina Konovalova, Maxim Nikolaev, Andrey Kuznetsov, et al.
Skywork-Reward-V2:通过人机协同扩展偏好数据管理
偏好
数据集
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, et al.
LangScene-X:利用TriMap视频扩散重建可泛化的3D语言嵌入场景
统一多模态
3D 生成
Fangfu Liu, Hao Li, Jiawei Chi, et al.
基于图像的多模态推理:基础、方法与未来前沿
多模态
推理
Zhaochen Su, Peng Xia, Hangyu Guo, et al.
WebSailor:用于网络代理的超人类推理导航
Agent
推理
Kuan Li, Zhongwang Zhang, Huifeng Yin, et al.
EmoBench-M:面向多模态大语言模型的情感智能基准测试
情绪识别
多模态
He Hu, Yucheng Zhou, Lianzhong You, et al.
机器学习中的AI研究代理:在MLE-bench中进行搜索、探索与泛化
强化学习
AI for Science
Edan Toledo, Karen Hambardzumyan, Martin Josifoski, et al.
局部感知的并行解码用于高效的自回归图像生成
图像生成
Transformer
Zhuoyang Zhang, Luke J. Huang, Chengyue Wu, et al.
FreeMorph:无需调参的扩散模型通用图像变形
扩散模型
图生图
Yukang Cao, Chenyang Si, Jinghao Wang, et al.
视觉-语言-动作模型综述:从动作分词的角度出发
多模态
自然语言处理
Yifan Zhong, Fengshuo Bai, Shaofei Cai, et al.
在任意条件下测量任何深度
深度估计
机器视觉 3D
Boyuan Sun, Modi Jin, Bowen Yin, et al.
LongAnimation:基于动态全局-局部记忆的长动画生成
视频生成
视频理解
Nan Chen, Mengqi Huang, Yihao Meng, et al.
快手 Keye-VL 技术报告
视频理解
多模态
Kwai Keye Team, Biao Yang, Bin Wen, et al.
自动驾驶中视觉-语言-行为模型的综述
多模态
自动驾驶
Sicong Jiang, Zilin Huang, Kangan Qian, et al.
MoCa:模态感知的持续预训练生成更优的双向多模态嵌入
多模态表征
Transformer
Haonan Chen, Hong Liu, Yuping Luo, et al.
FreeLong++:通过多频带谱融合实现无训练长视频生成
视频生成
文生视频
Yu Lu, Yi Yang
超越符号:从脑启发智能到人工通用智能的认知基础及其社会影响
Agent
推理
Rizwan Qureshi, Ranjan Sapkota, Abbas Shah, et al.
数学推理是否提升通用大语言模型的能力?理解大语言模型推理的可迁移性
监督式微调
模型训练
Maggie Huan, Yuetai Li, Tuney Zheng, et al.
SciArena:科学文献任务中基础模型的开放评估平台
LLM
偏好
Yilun Zhao, Kaiyan Zhang, Tiansheng Hu, et al.
医学中的整体人工智能:性能提升与可解释性增强
多模态
多模态表征
Periklis Petridis, Georgios Margaritis, Vasiliki Stoumpou, et al.
evolving prompts in-context: 一种开放式的、自我复制的视角
LLM
推理
Wang, Jianyu, Hu, et al.
SPIRAL:零和博弈中的自我对弈通过多智能体多轮强化学习激励推理
强化学习
推理
Bo Liu, Leon Guertler, Simon Yu, et al.
面向听者的奖励性思考在视觉语言模型中的图像偏好研究
偏好
推理
Alexander Gambashidze, Li Pengyi, Matvey Skripkin, et al.
Calligrapher:自由风格文本图像定制
扩散模型
文生图
Yue Ma, Qingyan Bai, Hao Ouyang, et al.
VMoBA:视频扩散模型中的块注意力混合方法
Transformer
视频生成
Jianzong Wu, Liang Hou, Haotian Yang, et al.
SMMILE:一种专家驱动的多模态医学情境学习基准
多模态
基准
Melanie Rieff, Maya Varma, Ossian Rabow, et al.
自动LLM速通基准:重现NanoGPT改进
基准
LLM
Bingchen Zhao, Despoina Magka, Minqi Jiang, et al.
Shape-for-Motion:基于3D代理的精确一致视频编辑
3D 模型
视频处理
Yuhao Liu, Tengfei Wang, Fang Liu, et al.
从理想到现实:面向实际场景的统一且数据高效的密集预测
语义分割
多任务学习
Changliang Xia, Chengyou Jia, Zhuohang Dang, et al.
ShotBench:视觉-语言模型中的专家级电影理解
视觉问答
多模态
Hongbo Liu, Jingwen He, Yi Jin, et al.
XVerse:通过DiT调制实现一致的多主体身份和语义属性控制
文生图
扩散模型
Bowen Chen, Mengyi Zhao, Haomiao Sun, et al.
24孔板中的零样本抗体设计
AI for Science
多模态
Chai Discovery Team
1
41
42
43
44
45
46
47
48